

介绍
计算机辅助工程(CAE)从上世纪50年代起源于数学家、科学家和工程师开发的技术,旨在改进航空航天和汽车工业的设计。作为一种资源密集型技术,CAE一直是一个等待解决方案的挑战。
随着半导体工艺驱动摩尔定律的每一次转动,内存的每一次进步以及CPU和GPU的并行处理能力的不断增强,CAE的性能也随之扩展。今天,CAE正在回应半导体和软件方面的进步,这些进步从根本上改变了行业格局。
主要的工程仿真软件供应商,包括Altair、Ansys、Autodesk、Dassault Systèmes(Simulia)、Hexagon MSC和西门子,一直依赖于当CPU是主要计算引擎时开发的技术。最初,为了适应计算系统,模型被简化了,但工程师想要更多的逼真和复杂度。因此,这些更大更复杂的问题的计算时间可能需要几个小时,甚至几天和几周的处理才能得到结果。
这延迟了结果的解释,因此也帮助定义了CAE的使用方式。例如,CAE通常在产品制造后用于鉴定故障原因。然而,CAE的真正价值在于在设计过程的早期阶段就开始使用。CAE更适合用于帮助定义设计,而不是诊断故障。
2000年图形处理器(GPU)的出现为CAE带来了一次重大转变,就像其他许多受益于并行处理的领域一样。CAE的主要工作是大规模的并行处理。CAE通过在模型上创建节点网格,然后对节点施加力和条件来评估设计是否适合其用途。网格越密,模拟越可靠。这是GPU的明显应用,软件供应商和硬件开发人员在GPU历史的早期就已经认识到这一点了。
为了在CPU上运行,仿真方法必须考虑到CPU的能力。他们必须减小模型的大小,简化设计,并管理网格大小,因此评估的实体可能与正在分析的真实实体存在很大的不同。
GPU的优势在于在一个芯片上拥有比CPU更多的处理单元。在处理器对比中,GPU处理器比CPU处理器便宜得多。那么,如果GPU处理器比CPU处理器更便宜,并且GPU更适合于CAE工作负载,为什么不所有软件程序都转换到GPU呢?
挑战在于GPU和CPU的工作方式不同,需要针对每个进行特定的编程方法。CAE基于几十年前开发的复杂应用程序。将这些程序适应GPU并不容易,但编程工具如Nvidia的CUDA和OpenCL已经出现,使开发人员更容易利用GPU加速。
CAD的变化
21世纪初,CAE出现了两个主要趋势。在2000年代的第一个十年,计算机辅助设计(CAD)软件供应商开始收购CAE技术,将其添加到设计流程中。这样做的想法是将CAE能力集成到CAD中,并自动化设计师的流程。这项工作正在进行中,收购也在继续。
同时,CAE社区也认识到需要先进的CAE,需要专业技能和资源。CAE软件供应商正在投资于GPU加速和推进高性能计算(HPC)。
同样,半导体公司一直在投资于为软件开发人员创建通往其硬件的工具。英特尔和AMD正在寻找其CPU和GPU的机会。Nvidia以其于2006年早期对CUDA的承诺和投资脱颖而出。CUDA是一组用于加速应用程序的GPU专用代码库。作为这项工作的一部分,Nvidia一直在与CAE开发人员合作,创建针对模拟-分析-可视化常见任务的工具。该公司独特的是其对GPU的专注,这推动了其进入专业工具开发领域。在2023年,这种专注有望通过Nvidia的Grace CPU的推出而扩大,该CPU将利用Arm处理器以及CPU。
在CPU和GPU之间,CAE的路径分化。集成到CAD流程中的分析工具具有更高的自动化水平,并且设计用于更简单的问题; 它们允许CPU的限制,并通过使可视化和模拟工具对设计师和工程师可访问来帮助增长CAE工具市场。早期的模拟工具依赖于CPU,因为CAD程序是为CPU编写的。如今,CAD供应商正寻找像模拟行业中的同行一样利用GPU的方法。CAD供应商正在构建插件和附加组件以实现GPU加速。此外,它们正在添加云资源,以提供对其CAD旗舰产品的基于CPU的核心技术不可用的高级功能。这些进步为包括分析和模拟的工作站应用程序提供了发展空间。
举一个著名的例子,达索系统公司已经构建了他们的3DExperience平台,以统一Catia和SolidWorks设计平台。在3DExperience平台上工作的设计工程师可以直接在其设计上使用Abaqus进行结构分析,并利用该程序对GPU加速的支持,而无需导入CAD模型,执行网格划分,运行分析,然后在单独的工具中更新设计。基于云的CAD工具Autodesk Fusion 360和PTC的Onshape也可以利用云中的GPU来进行程序的模拟扩展。
尽管在主流设计应用程序中工作的CAE应用程序的机会正在增长,但仍将有对需要专业从业者进行高端分析的同时需求。设计师在工作时执行简单分析的能力为高性能系统进一步发展的先进模拟铺平了道路,无论是工作站、HPC服务器还是基于云的系统。
GPU工具不断发展
传统上,设计师和工程师会导出他们感兴趣区域的简化模型。他们会尽可能地删除模型的特征并添加网格作为分析的框架。他们还会定义材料并施加载荷和约束。这些步骤是CAE的预处理阶段的一部分。 传统上,该过程由专家处理,往往是一个耗时的过程。集成在CAD程序中的仿真工具通常会自动化处理简化几何的过程。在更高级的实现中,该过程可能是手动和自动化过程的结合。驱动力是通过在工作站上增加自动化来避免等待经验不足的用户和甚至专家可能会忽略需要特别关注的区域的挑战。
此外,对于预处理和识别模型中的关注区域,越来越多地出现了使用机器学习(ML)和人工智能(AI)的趋势。
准备好的预处理自定义几何将被发送到求解器。

一旦网格被定义好后,接下来就是最繁重的任务:求解。这包括运行计算流体力学(CFD)、有限元分析(FEA)和计算电磁学(CEM)模拟的算法,根据问题的不同,可能需要一些时间——几分钟、几小时,甚至几天——取决于应用程序和工作负载的要求。
GPU的最佳路线
自2014年以来,每个主要的CAE供应商都以某种方式利用了GPU加速。对求解器方面的算法进行了大量的工作,因为可以实现巨大的收益。估计线性求解器占CAE工作量的50-70%。对于一些软件供应商而言,在某些情况下,这代表了低果实,因为该过程易于映射到GPU。在其他情况下,代码必须被重写。
例如,AMG(代数多网格)算法是所有CFD软件工具中心的求解器。 Nvidia和Ansys合作并将AMG并行化,并创建了AmgX库以利用GPU,然后进一步开发CUDA工具用于CFD。
这项工作促使Ansys开发了一款新产品Discovery,它正在转变主流CAD工具中的仿真工作流程,允许在流体,热,结构和模态应用中进行迭代式设计探索。

Ansys公司研究副总裁Dipankar Choudhury表示,Discovery的开发代表着Ansys从传统产品中脱颖而出,这些产品通常是为设计周期的末尾而开发的。他说:“Discovery实际上将设计过程向上推进。因此,使用Discovery技术,您可以评估候选设计,还可以在早期评估设计概念。”
对于Discovery,Ansys抓住机会从GPU的角度重新设计,而不是移植像他们的Fluent CFD工具这样的大型应用程序。“我们不会进行移植,” Choudhury说。仿真公司在过渡到GPU加速时正在处理的挑战是,为CPU编写的代码部分可能会降低总体性能。
“因此,我们非常有意识地决定不采用这种方法,并从头开始在GPU上编写代码软件。” 在Discovery的开发之后,PTC和Ansys合作推出了Ansys Discovery,Creo Simulation Live的集成版本,使设计师可以进行迭代设计和分析。
西门子并没有急于进入GPU市场,而是等待他们感到投资将使用户受益。他们的过渡到GPU的方法是基于这样一种假设:他们的客户将能够毫不费力地在CPU和GPU之间无缝切换,而不会对他们的模拟环境和结果产生任何影响。随着C++工具成熟度的提高和Nvidia Volta架构带来的性能改进,他们感觉现在是时候了。
西门子的CFD软件Simcenter STAR-CCM+是一个庞大的代码库,但是大多数更改都是在内部框架层面进行处理的。西门子的开发人员修改了框架,支持一个单一的代码库,可以统一地编译为CPU和GPU架构,内部细节被抽象出来。为了在2022年初通过Simcenter STAR-CCM+ 2022.1交付他们的第一个GPU版本,他们依赖于NVIDIA的AmgX。对于这个版本,他们专注于车辆外部空气动力学应用,因为这项工作需要较少的物理模型和相关框架的移植,但是计算开销很大,使并行化成为必需,GPU加速非常有吸引力。随后,西门子的工程师正在大力投资于将所有可以从GPU受益的物理、求解器和相关软件部件移植到未来几年中。
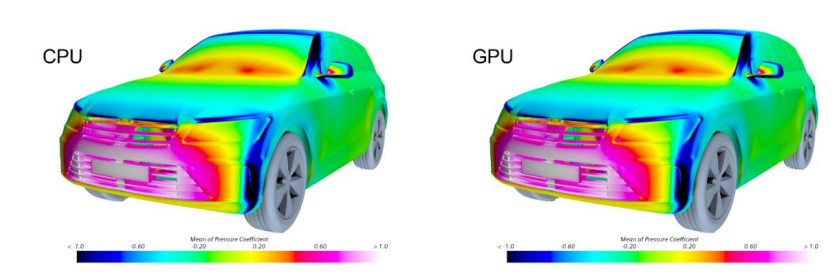
Simcenter STAR-CCM+物理领域的产品经理Stamatina Petropoulou表示,西门子相信异构架构是未来的发展方向。在寻找任何给定仿真项目的最佳成本解决方案时,CFD工程师将希望从CPU切换到GPU,从本地切换到云端,甚至在一个单一的仿真运行中利用所有的优势。她指出,“对于多年来一直在验证软件结果一致性的Simcenter STAR-CCM+客户来说,无缝切换CPU到GPU非常关键!”因此,他们确保客户可以使用相同的代码,并在CPU或GPU上获得等效的结果(参见图像)。
Hexagon公司的产品管理副总裁Hugues Jeancolas表示,在MSC Software中,他们决定从一开始就为GPU编写其新产品MSC Apex Generative Design。他说,结果是,该应用程序在使用Nvidia GPU进行计算时,可以运行以前需要昂贵集群才能运行的计算。CUDA框架为Hexagon的开发人员提供了一个易于入门的起点,他们能够立即开始编码。MSC开发团队使用MSC Apex Generative Design、CUDA、CuBLAS和CuSPARSE来实现其生成式设计应用程序的GPU加速。
最后,MSC Apex Generative Design会输出一份完整的、可供添加制造机器使用的模型,无需手动重新处理。Jeancolas估计,标准部件的一个优化运行的计算时间可以通过在标准工作站上比较CPU和GPU来缩短五倍。他说,随着添加更多的GPU或使用更先进的GPU,这个数字会不断提高。 同样地,Hexagon的工程师们能够重新设计他们的Actran DGM(不连续Galerkin方法)声学应用程序,以利用GPU。Actran DGM用于预测复杂物理条件下的噪音传播,广泛应用于汽车工业。Jeancolas表示,大约十年前,在GPGPU(通用GPU)应用程序的早期阶段,Actran DGM团队能够将他们的大部分代码移植到GPU上。这个基于CPU的代码是大规模并行的,需要数千个核心。通过将其移植到GPU上,团队不仅使代码更加高效,而且由于CPU核心比GPU核心更昂贵,运行成本也更低。 如今,Actran DGM已经被优化以进一步利用GPU加速。Actran DGM的性能随着GPU数量的增加而增加。性能还取决于板上的内存容量、每个单独核心的性能和核心数量,这些条件随着引入新的图形板和GPU而不断提高。
在将CAE程序适配为GPU加速的早期阶段,电磁分析已成为GPU加速的早期受益者。2016年,达索系统收购了德国公司(CST),该公司专门从事电磁仿真和分析软件,以扩展其Simulia品牌的多物理学组合。达索系统Simulia R&D电磁技术高级总监Peter Hammes表示,CST Studio Suite的技术基于有限差分时域仿真算法,非常适合GPU架构。它还受益于大型GPU内存和内存带宽,并且从工作站GPU扩展到数据中心计算GPU(例如Nvidia A100)的能力非常好。CST团队认为,Nvidia的CUDA库使得从零开始开发新项目变得更加容易。
Altair于2019年收购了EDEM,并将其离散元素建模技术加入其庞大的求解器技术组合中。EDEM可以作为独立工具使用,也可以与其他CAE工具结合使用,包括与CFD求解器结合使用,用于与基于颗粒的材料行为相关的模拟。它用于模拟煤和其他矿石、土壤、纤维、谷物等的行为。处理基于颗粒的模拟已经是天然的大规模并行任务。
“实际开发过程非常顺利,客户在性能方面看到了巨大的回报——相比基于CPU的流程,性能提高了20倍,”Altair高级副总裁兼CFD副总裁David Curry说。“具体来说,添加GPU将EDEM的性能提高了20倍,相当于12个CPU在类似的工作负载下工作。”Altair表示,他们最新的EDEM多GPU求解器可以解决规模更大的工业问题——包括数百万粒子,随着添加更多GPU卡,性能可扩展性得到提高。 据Curry表示,大规模GPU系统的部署增加了人工智能应用的热情。人工智能有助于通过主要云服务提供商增加云GPU的可用性,进而推动GPU加速工具和应用的稳定增长。 Altair的工程师开始支持GPU,因为GPGPU开发工具变得更加可用。他们认为,Nvidia不断更新技术、开发工具和支持使这个过程更容易。 迄今为止,来自10多个独立软件开发商的120多个CAE应用程序已经通过GPU加速。结果令人印象深刻,根据应用程序和工作负载的不同,速度提高了多达100倍。此外,随着添加GPU,性能改进将不断扩大。随着更多求解器移植到GPU,还将出现更多的突破。
客户
在CAE的最后阶段,包括可视化、结果分析和报告撰写时,人的因素变得非常重要。CAE应用程序提供了可视化和相关数据的结果。分析人员评估结果,并决定如何继续——进行更多分析或返回模型进行调整,如分析所建议的那样。
即使分析过程是从CAD模型内部启动的,分析通常也是一个与设计分离的过程。正如我们已经概述的那样,几何优化、网格化、分析、可视化和评估。然后将发现带回来调整设计几何,进行更多分析或推进设计。
在使用高级分析的情况下,该过程甚至更为不连贯,因为分析本身可能是在设计组之外甚至由不同的公司执行的外部过程。最近由Roopinder Tara为Dassault Systèmes编写的一项研究《模拟、原型和验证的状态》记录了类似的工作流程。他们对268名工程师进行了调查,发现实际的CAE实践滞后于当今的计算机和软件潜力。物理原型仍在制作中,设计仍被发送到外部专家进行分析,这可能需要数天才能完成。
开发Discovery的Ansys团队认为他们正在为分析开辟一条新路。Ansys产品管理总监Justin Hendrickson表示:“我们有点奉行‘建设它,他们就会来’的模式。”Dipankar Choudhury也同意,并表示他们看到了Discovery在公司中被介绍的方式以及它如何被学校教师教授的变化。Discovery不再只是研究部门和研究生使用,而是直接传递给最终用户并由初等教育教师教授。数字也支持在整个设计过程中使用GPU加速。Discovery团队为创建Discovery所做的工作也为他们在Fluent上的工作提供了启示。Discovery的CFD部分也成为Ansys的Fluent的基础。
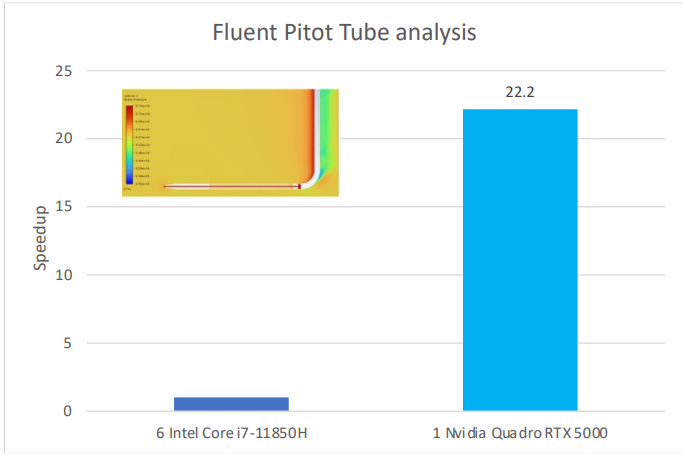
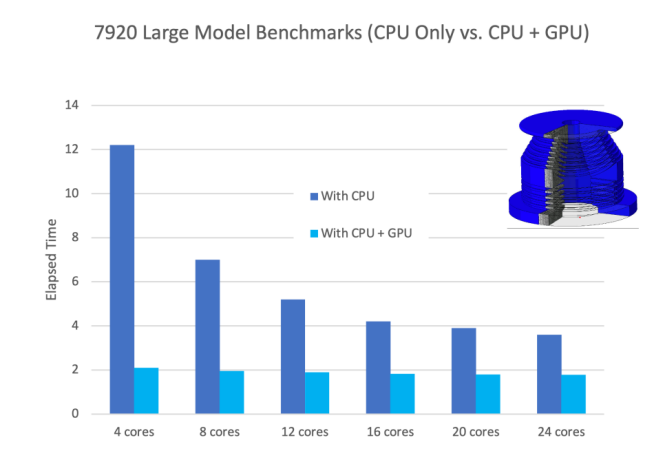
使用一个Quadro RTX 5000 GPU的工作站,而使用六个Intel Core i7-11850H CPU。
Choudhury指出,随着GPU开始在像CAE这样的高级计算过程中发挥作用,“传统的计算社区总是认为我们选择的方法精度较低,或者我们在数值方法上做出妥协以便使它们在GPU上高效运行。”但事实并非如此,Hendrickson说。他们看到了同样精度的结果,“这真是令人惊讶,也不是预料之中的,”他补充道。“当我们看到GPU的一些好处时,其中一个是速度,但是速度意味着什么?
我们真正谈论的是每美元的价格、每核的性能或每美元的性能。”他说,Ansys的许多客户都关心可持续性,他们关心能源最小化,正是在这两个方面,我们看到了10倍甚至更大的增长。”

加快Ansys最新版本的Fluent在GPU上原生运行,并且速度加快
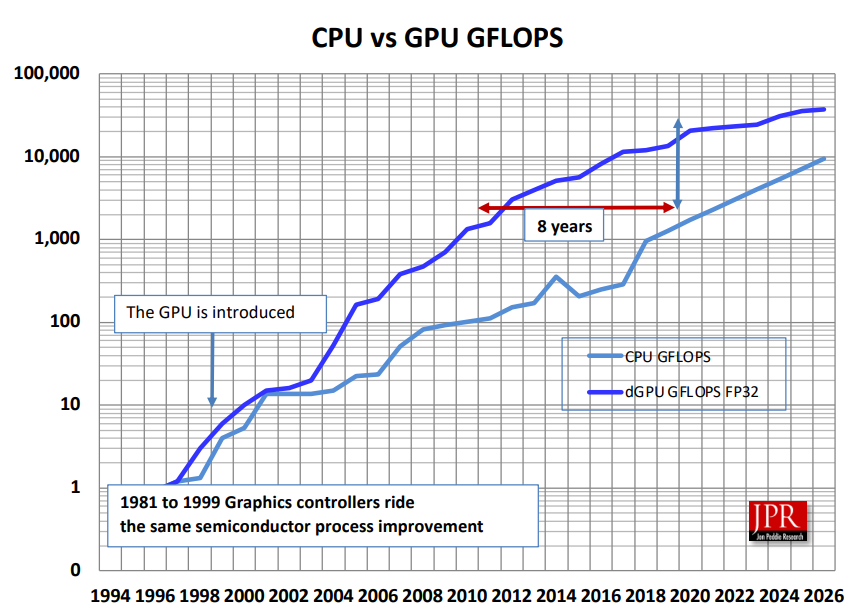
Ansys的科学家们已经计算出,在某些情况下,四个GPU在某些CAE应用程序中可以比一千个CPU内核表现更好,成本只有其16%,并且耗电量比后者少四分之一。该公司已发布一篇博客,讨论了GPU在CFD应用中的可扩展性。该博客还强调了CPU和GPU之间有吸引力的成本差异。在桌面上,随着新一代处理器的推出,CAE性能可以随之提升,因为新的半导体制造工艺使每个内核具备了更多的处理器。
相比于CPU,Nvidia GPU在内核数或每秒浮点运算(FLOPS)方面表现更好。由于算法的冗余性和数据量的多样性,网格处理和求解程序非常适合并行处理器。
Dassault Systèmes的Simulia首席架构师Matt Dunbar表示,主要用于结构模拟的FEA工具Simulia Abaqus受益于GPU处理器的快速发展。他表示,在过去,“每当你将计算能力加入代码中时,人们就会使问题更大。”这种趋势不再是一个硬性规则,因为客户希望能够执行更多的迭代,同时解决更具挑战性的问题。他指出,现代工作站可以拥有大量的内存和大量的核心。现在,“在工作站中添加一个或两个GPU确实可以使工作站获得强大的加速效果,扩展了工作站的范围,而不需要强制转向高性能计算(HPC)。” GPU加速对于几个Abaqus功能都是有益的,包括使用AMS特征解算器,在节点数量非常大的完整车辆模型中提高自然频率提取性能。 GPU计算资源对于Abaqus稳态动力学和计算密集型的直接稀疏求解器操作也非常有益。

随着工作站在高级计算过程方面的能力越来越强,它们在设计工作流程中的作用也在发生变化。高级功能也正在改变那些使用这些计算机的人们的角色,现在他们能够在自己的办公桌上完成更多的工作。
更多
显然,相比于在CPU上运行类似应用程序,GPU加速了CAE过程。简单来说,在单个芯片中,GPU处理器比CPU半导体中的处理器多一个数量级,但这不是一场纯粹的数字游戏。应用程序必须经过GPU优化,硬件平台需要针对仿真进行优化,并且每个问题都有其自身的要求。
正如本文中提到的,一些应用程序,例如电磁仿真、粒子和声学仿真,非常适合于GPU。此外,GPU喜欢大型问题,这就是为什么我们看到Ansys和西门子推出了改进的CFD应用程序的原因。问题越大,仿真越有效率。 为了评估小型和大型模型仿真的改进情况,达索系统与戴尔和《数字工程杂志》合作,测试了搭载双Intel Xeon Gold 6146 3.2 GHz GPU和Nvidia Quadro GV100的2021 Dell Precision 7920 Tower。
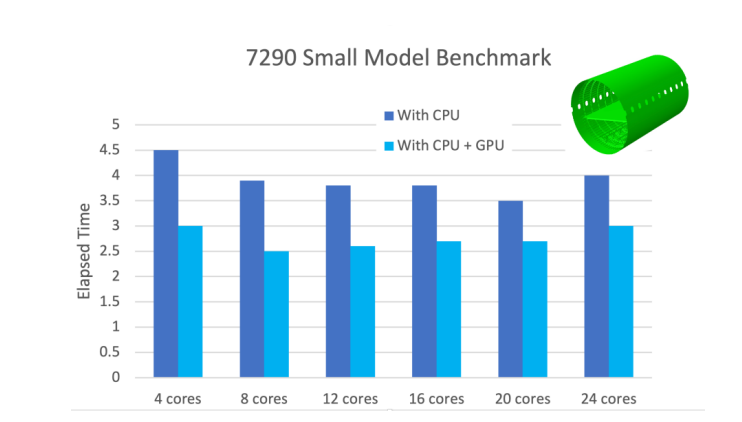
成本效益显而易见。GPU处理器比CPU更便宜。无论是云端、集群还是台式机上使用GPU都是如此。
除了快速的CPU和GPU,CAE工作负载还受益于大缓存和宽带宽。重要的是确保内存不成为瓶颈,因此在许多情况下,CAE工作流正在转移到图形板上,这就是为什么我们看到专业图形板带有大量高速内存的原因。
Ansys在其博客中表示,将GPU用于CAE工作负载的好处包括:
•提高性能。
•降低硬件成本。
•减少能源消耗。
结论
我们所询问的开发人员的经验清楚地表明,与CPU相比,GPU在性能和成本方面具有优势。针对渲染、CAE、AI/ML、视频编辑和游戏等需求,GPU的广泛可用性和不断增长的数量,确保几乎所有的功能强大的工作站系统都配备有GPU,通常是非常强大的GPU。
此外,GPU在这些资源密集型应用程序(如模拟)中卸载CPU的作用确保了整个系统的效率。 由于这些原因,GPU加速,曾经是设计和工程的一个很好的组件,现在已成为公司推进其实践的关键组成部分。
随着数字孪生的概念引起行业的想象力,CAD行业正在迅速变化。我们预计随着技术的不断改进,桌面上的迭代将更快、更便宜,更复杂的分析(和更大的几何体)将利用强大的HPC设备。
想了解更多CAE相关信息 欢迎扫码关注小F(ID:iamfastone)获取
我们有个CAE仿真研发云平台
集成多种CAE/CFD应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送200元体验金,入股不亏~

更多电子书
欢迎扫码关注小F(ID:imfastone)获取

你也许想了解具体的落地场景:
王者带飞LeDock!开箱即用&一键定位分子库+全流程自动化,3.5小时完成20万分子对接
这样跑COMSOL,是不是就可以发Nature了
Auto-Scale这支仙女棒如何大幅提升Virtuoso仿真效率?
1分钟告诉你用MOE模拟200000个分子要花多少钱
LS-DYNA求解效率深度测评 │ 六种规模,本地VS云端5种不同硬件配置
揭秘20000个VCS任务背后的“搬桌子”系列故事
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
关于为应用定义的云平台:
2023仿真宇宙漫游指南——工业仿真从业者必读
当仿真外包成为过气网红后…
和28家业界大佬排排坐是一种怎样的体验?
这一届科研计算人赶DDL红宝书:学生篇
杨洋组织的“太空营救”中, 那2小时到底发生了什么?
一次搞懂速石科技三大产品:FCC、FCC-E、FCP
Ansys最新CAE调研报告找到阻碍仿真效率提升的“元凶”
国内超算发展近40年,终于遇到了一个像样的对手
帮助CXO解惑上云成本的迷思,看这篇就够了
花费4小时5500美元,速石科技跻身全球超算TOP500






