
问:实验室的硬件条件好坏对你的科研有多大影响?
答:啥条件都行,没有影响。

我们坚信以下三点:
1、科学家就是专门负责搞科研的;
2、不依赖别人,你的研究效率和节奏必须掌握在你自己手里;
3、不管是尝试有风险的新颖项目,还是运用深度学习手段,科研多试错才能出好东西。
有老师跟我们吐槽说,一天天地忙着维护环境,整得跟运维工程师一样了,太耽误事儿。想找学生帮忙吧,他们很多也不懂啊~
老师们的硕博后们也苦不堪言,本专业要学的东西已经多到爆炸,又要理论还要搞实验,还要学大量计算机专业知识……
你这边数据刚拿到手,别人文章都发了……救救孩子吧。
守着大把机器的,不见得有恃无恐;
得不到的,永远在骚动,甚至还会掉头发。。。

我们为这一届科研计算人准备的赶DDL红宝书分为上下两篇:
《学生篇》
一、你们具体怎么帮我们搞科研的?展开说说
二、在云上和在本地跑任务有什么区别?
三、我自己也会上云,为啥要选你们?
四、你们跟超算比怎么样,有区别吗?
《老师篇》
五、我是一个老师,你们对我的科研工作/团队管理有什么帮助?
六、我是药物/生物/化学专业方向的,你们能做到什么程度?
七、我是集成电路/微电子专业方向的,你们能做到什么程度?
八、我是力学/热能/机械工程专业方向的,你们能做到什么程度?
你想问的,这里都有答案。
你想要的,我们能提供更多。
以下是学生篇
一 、你们具体怎么帮我们搞科研的?展开说说?
1、你们面向的是哪些科研方向的人?
四大类:
集成电路/微电子专业方向,包括物理电子学/电路与系统/微电子学与固体电子学等专业;
药物/生物/化学专业方向,包括生物化学与分子生物学/化学工程/生物化学/生物工程/药物化学/分析化学/高分子化学与物理等专业;
力学/热能/机械工程专业方向,包括流体力学/工程力学/机械制造及其自动化/车辆工程/工程热物理/热能工程/动力机械及工程/流体机械及工程/航空宇航制造工程等专业;
以及高校或科研机构的AI训练平台、虚拟仿真实验室等等。
2、你们是怎么帮助我们这些搞科研的人的?
两点结论:
1、让大家更专心做科研,提升高校及科研机构师生的整体科研效率,让IT能力跟上科研能力。
2、避免大家因为资源不够而不得不选择短平快的研究,不敢尝试。
具体分成以下四个维度:
一整套针对应用优化的自动化科研环境,即开即用;
海量资源加智能决策辅助,大幅提升计算效率同时降低成本;
有针对老师需求的独特场景(这一点后续单独展开);
让IT能力跟上科研能力,可视化操作,轻松上手。
3、你们是通过哪些手段大幅提升计算效率的?
应用云端优化、即开即用的云平台、云端海量资源、Auto-Scale、调度器……
具体可见以下实证:
Auto-Scale这支仙女棒如何大幅提升Virtuoso仿真效率?
1分钟告诉你用MOE模拟200000个分子要花多少钱
LS-DYNA求解效率深度测评 │ 六种规模,本地VS云端5种不同硬件配置
揭秘20000个VCS任务背后的“搬桌子”系列故事
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
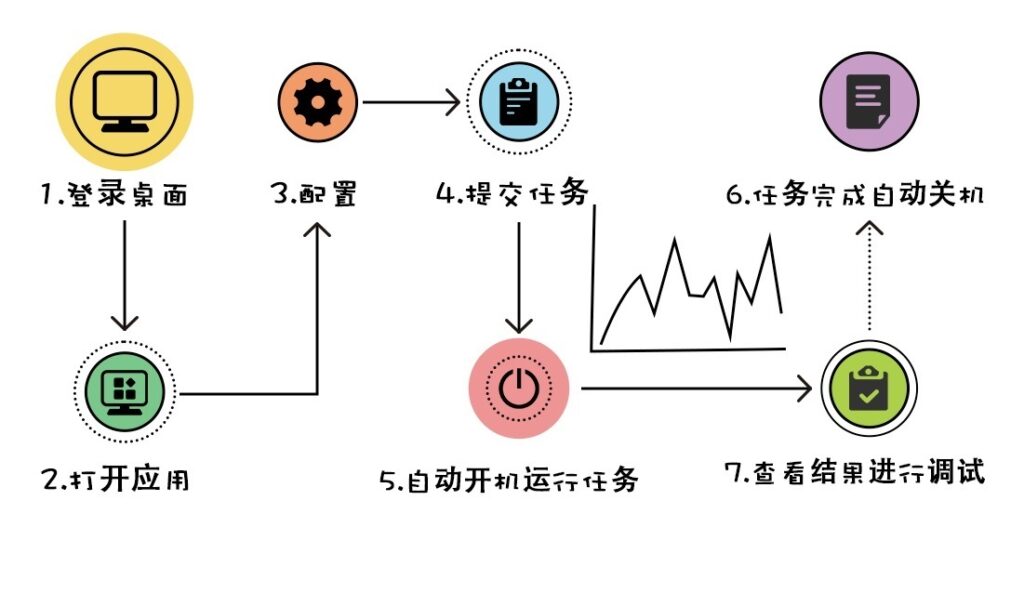
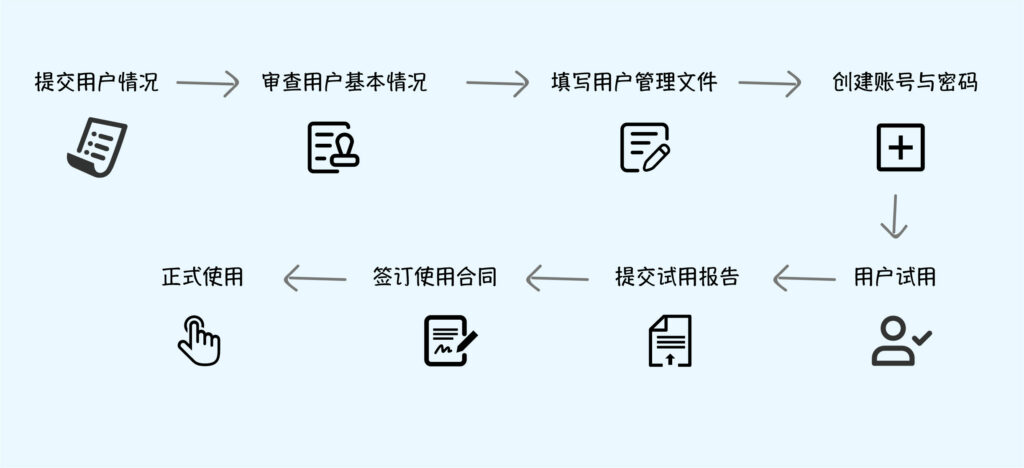
4、一整套科研环境指什么?
包括了应用环境和底层的运行环境。
我们为用户提供从登录桌面、打开应用、配置、提交任务、自动上云开机运行任务并自动关机、查看结果进行调试……用户所需要的操作与本地几乎完全一致,每一步只需在平台上使用鼠标简单点选即可完成。
5、具体降低了什么工作量?
整套自动化环境避免了大量手动操作,也降低了出错概率。
工具的最大价值,是把人从机械性的重复劳动中解放出来,腾出时间来思考更重要的事。
比如,一百个任务一个个手动写?一百台机器一个个登陆上去装应用,配置环境?任务跑着跑着失败了,手动一个个重来?
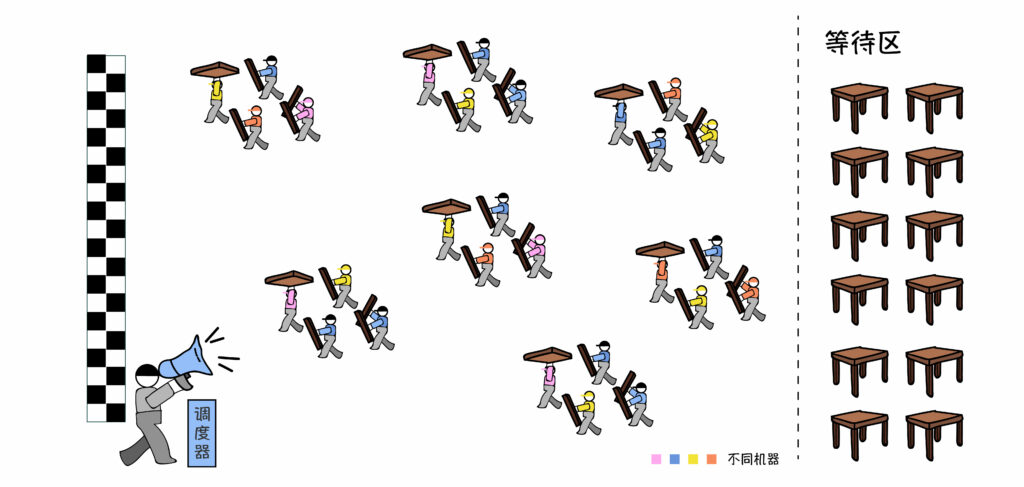
避免重复劳动,一次操作完成所有需要手动一次次做的事,一百次就忍了,一千次,一万次呢?
也不需要团队每个人重复一遍同样的学习过程,做个模板它不香吗?
6、你们说的应用或者任务,指的是什么?
药物/生物/化学/集成电路/微电子/力学/热能/机械工程/人工智能专业相关的软件/工具。
药物/生物/化学方向的有 Autodock Vina、NetMHC、Qvina、Amber、MaterialsStudio、GATK、VASP、Rosetta、Schrödinger、BCFtools、Gromacs、FastQC、DeltaVina、Gaussian等;
集成电路/微电子方向的有 Innovus、Spectre、Genus、Dracula、Virtuoso、Ncsim、PowerSI、Xcelium、PT、DC、VCS、VC、FM、Verdi、OPC Proteus、Tmax2、HSPICE、Spyglass、Starrc、Calibre、Tessent、nmLVS、nmDRC、xACT、xL、xRC等;
力学/热能/机械工程方向的有 Abaqus、Autodesk、Bladed、CFX、COMSOL、Fluent、HyperWorks、LS-DYNA、Matlab、Mechanical、MSC Adams、MSC Nastran、StarCCM、SOLIDWORKS、VASP、WRF等;
人工智能方向的有 Pytorch、Mxnet、Tensorflow、Caffe2、Miniconda、Scikit Learn/OpenCV、Pylearn2、Keras等。
7、你们和这些软件/工具,有什么区别呢?
一句话概括,我们是EDA/CAE/CFD/生物/化学/AI计算云平台,通过我们可以在短时间内调集海量资源,为上述软件/工具加速,从而抢在各种科研deadline之前跑完任务,拿到结果。
关于我们的其他优势与技术能力,可以通过后面的问题了解。
8、你们哪里来的计算资源?
目前我们从多家云厂商调集海量多云资源。
9、有时候为了抢几台机器都要跟实验室的师兄弟姐妹斗智斗勇,你们的资源真有那么多?
云上资源非常多,我们曾经根据IDC报告推测国内云厂商的服务器总量超过116万台,2020年中国公有云服务市场的全球占比为6.5%,可大致估算出全球公有云厂商的服务器总量超过千万台。
重点是,这些机器都是可用资源。
10、支持AWS/华为云/GCP/Azure/阿里云/腾讯云……吗?
国内外主流云厂商我们都支持。
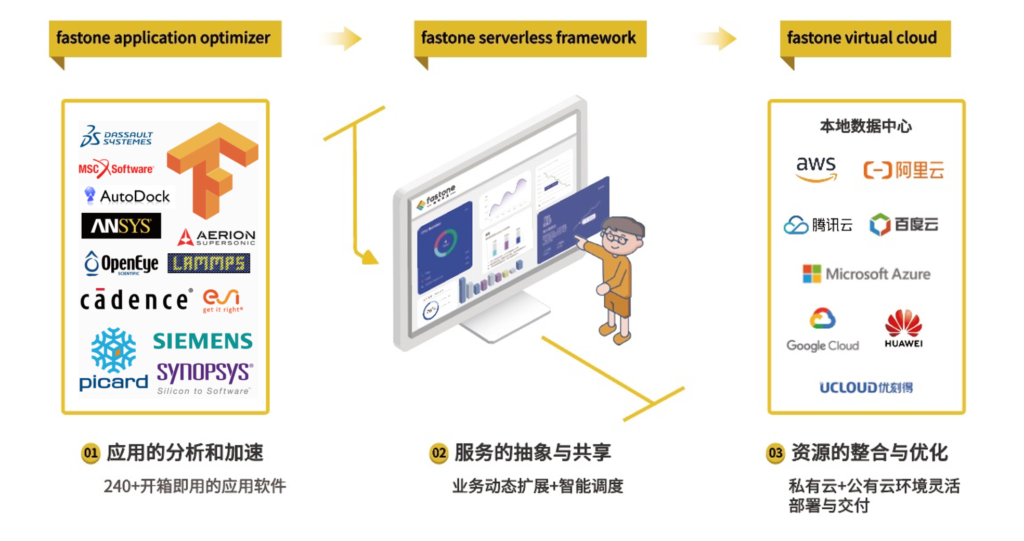
11、你们跟云厂商有什么区别?
我们是从应用出发,为应用定义的云平台。
而云厂商主要在IaaS层,距离用户的实际应用还有非常长的距离。
在云的基础架构和应用之间,需要借助应用优化、多云环境支持等方式来满足用户需求。
12、那我直接用云厂商是不是就行了?
参考上一个答案。
直接用云厂商需要做大量的IT调试,而我们已经对接了众多主流云厂商的API,可以用统一的方式方法完成自动化部署,简化用户使用云资源的方式,降低学习成本,帮助用户高效地用好云,将精力集中在科研任务上。
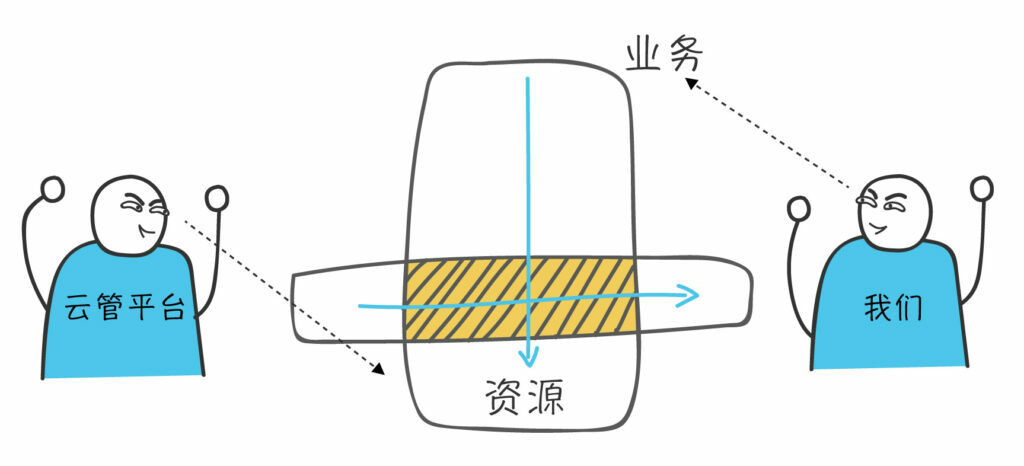
13、听说还有个云管平台,跟你们有什么不同?
我们更贴近应用,在云管平台之上。a具体可查看《灵魂画师,在线科普多云平台/CMP云管平台/中间件/虚拟化/容器是个啥》
14、之前上过云,发现有些类型的资源比较少(如部分型号的GPU),需要分别从几个不同云厂商调资源,你们支持吗?
我们支持多云。
多云指使用来自多个云厂商的多种服务,可以最大限度利用不同云厂商的不同优势,就像你说的从几个不同云厂商调资源。而在产品价格、地域选择,多云也更有优势。
15、云上的虚拟机靠谱吗?性能可以吗?
放心,性能相当,并可以更好。
两方面原因:
1、云上的硬件更新快(详见第54问);
2、云上虚拟化性能逐步接近裸机。
16、各个云之间的虚拟机性能有差异吗?我不会选怎么办?
有。我们可以为用户提供专业建议。
17、云上用的机型是超线程的还是物理核的?
大多数云厂商支持开启和关闭超线程。
18、我做的课题需要特定类型的计算资源,而且可能需要好几种,云上有GPU/大内存资源吗?
有,我们和云上的资源是保持同步的。
包括但不限于超大内存、超大硬盘、网络优化、GPU等资源,并且十分灵活,即开即用,随关随走。
我们对不同类型云端资源有非常详尽的研究分析,具体看《【2020新版】六家云厂商价格比较:AWS/阿里云/Azure/Google Cloud/华为云/腾讯云》

19、License在云上能正常用吗?
License无论在云上还是本地都能正常使用。
在这篇《EDA云实证Vol.4: 5000核大规模OPC上云,效率提升53倍 》中,我们将License Server分别部署在本地和云端,计算结果完全一致,集群运行均无中断,GUI启动均正常。
20、你们有自己的资源中心吗?
公有云以及第三方IDC合作共建的数据中心。
21、使用机器需要排队吗?
正常使用云上资源无需排队。
如果是上万核那种的,建议提前联系我们调配资源。
22、那启动机器需要多久?
除了特殊机型,启动单机的时间几乎可以忽略不计。
如果是集群,根据集群规模大小需要若干分钟的等待时间。
23、发paper、赶实验工期、开组会……我们经常会特别着急临时要跑一个任务,你们最快多久可以用上?
无需排队,即开即用,参考前两个问题。
24、半夜发现实验结果有问题,第二天就要交了,你们的资源随叫随到吗?
全程操作自服务,白天晚上没区别。
25、使用过程中遇到问题,你们有人支持吗?
我们大部分是自服务,如果你们遇到问题,我们也提供人工服务。
二、在云上和在本地跑任务有什么区别?
26、我现在常用的应用有好几个,都是直接放到云上就可以跑吗?
是的,我们不仅支持常规应用,也支持用户自定义安装。
原先在本地上怎么用,在云上就怎么用。
27、我在自己机器怎么跑应用,在云上就怎么跑吗?需要每次都配置吗?
不需要每次都配置。
一次配置,无限使用。
28、从来没上过云,你们的云平台用起来麻烦吗?
我们基本不会改变用户的使用习惯,配置完成之后,使用者跟原先的使用习惯是一致的。
我们支持WebVNC远程桌面接入和WebSSH远程命令行接入功能。
详见《CAE云实证Vol.5:怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?》
29、搞不定命令行,你们支持图形界面登录吗?
我们支持Linux VNC,也支持Windows RDP。
30、多机并行跑任务真的特别快吗?
云端的一大特点,就是你用相同的钱,可以让1台机器跑100小时,也可以让100台机器跑1小时,后者就是多机并行,能够大大节省跑任务的时间。
效果参考问题3。
31、所有的应用都可以靠多机并行来提升效率吗?
不是所有的应用都支持,我们可以基于经验为用户提供建议。
有些应用本身不支持多进程处理,有些应用虽然支持分布式但对分布式支持并不好,也就无法依靠多机并行来提升效率,但我们可以通过为其寻找更适合的机型、提升自动化程度等多个角度来提升效率。
不同机型对应用效率的提升有多大?看这篇《CAE云实证Vol.5:怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?》
32、使用你们的平台需要自己安装操作系统吗?
不需要,可以选择需要什么操作系统。
33、我跑的应用没有windows版本,你们支持linux系统吗?
支持。
34、云上可以支持集群吗?
可以。
我们支持LSF/SGE/Slurm集群。
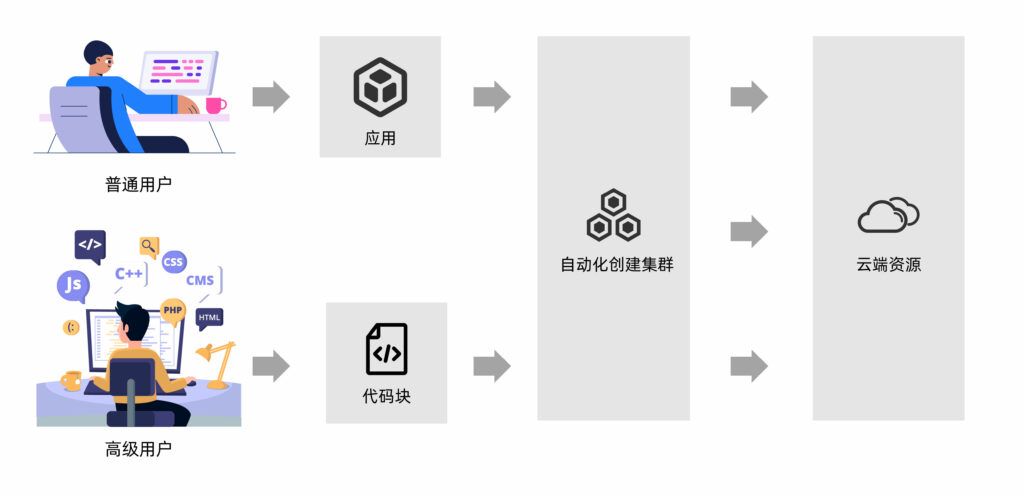
35、我习惯了自己写代码,能不能直接通过代码来调集群?
对于本身对应用工作流的理解和编程能力超强的用户,我们提供更高级用户模式,可以直接根据自己写的脚本,通过Web浏览器选择新建集群,然后按需动态地在云端创建HPC集群。
36、云上的集群也像本地一样需要一台台部署吗?
不需要。
传统IT模式下,通常都是先构建一个固定规模的集群,然后提交任务,当全部任务结束后再关闭集群。
我们实现了云上集群的自动化部署,只需点击几个按钮,5-10分钟即可开启集群,并在任务结束后自动关机。详情可参考《EDA云实证Vol.1:从30天到17小时,如何让HSPICE仿真效率提升42倍?》

37、访问集群会很麻烦吗?
访问集群,既可以通过命令行,也可以通过WebVNC图形界面方式直接访问。
我们为所有用户免费提供WebVNC功能,自动化创建到访问集群:
1、通过Web浏览器登录fastone平台;
2、在Web界面新建集群、配置资源;
3、在已创建的集群点击WebVNC远程桌面图标(同时提供WebSSH远程命令行功能);
4、跳转到虚拟桌面,可在该桌面中操作应用。
38、云端硬件该怎么选?有什么讲究吗?
需要根据具体的应用而定。
具体可参考下图:

三、我自己也会上云,为啥要选你们?
39、我之前用过云,为啥还要选你们?
我们对接了几乎所有的主流云厂商,多云的优势参见第14问。
我们还能带来许多其他方面的提升,具体可参考后面几个问题。
40、我们实验室里才几台机器,天天维护头就很大了,云上这么多机器还不得把自己搞秃了?
云上的运行环境都是自动化配置的,不需要人工干预,用户还可以通过平台进行统一管理和监控,方便易操作。
举个例子,我们的Auto-Scale功能可以自动监控用户提交的任务数量和资源的需求,动态按需地开启和关闭所需算力资源,在不够的时候,还能根据不同的用户策略,自动化调度本区域及其他区域的目标类型或相似类型实例资源。
所有操作都是自动化完成,无需用户干预。
下图就是开启Auto-Scale功能后,用户某项目一周之内所调用云端计算资源的动态情况。
其中橙色曲线为OD实例的使用状况,红色曲线为SPOT的使用状况。
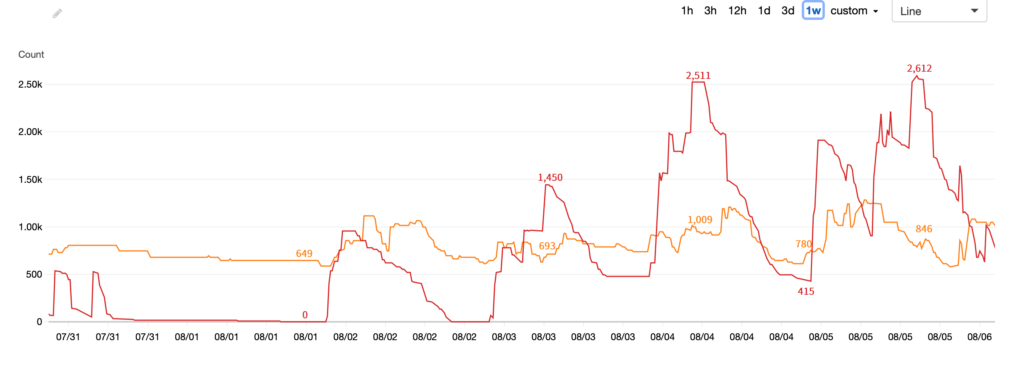
可以看到整个阶段算力波峰为约3500核,而波谷只有650核左右。Auto-Scale功能可以根据任务运算情况动态开启云端资源,并在波峰过去后自动关闭,让资源的使用随着用户的需求自动扩张及缩小,最大程度匹配任务需求。具体戳《EDA云实证Vol.10:Auto-Scale这支仙女棒如何大幅提升Virtuoso仿真效率?》
41、是不是可以认为你们就是个调度器?
调度器是我们平台的一个重要组件。

42、你们这个调度器是怎么个智能法?
我们是基于用户策略的双层智能调度。
上层调度程序支持灵活的用户策略:
-基于位置
-基于性能
-基于成本
-基于团队/组织目标……
下层调度程序满足应用要求:
-基于Slurm/LSF/SGE/PBS的工作任务
-基于容器的K8S工作任务……
智能调度用户策略详情看这个《生信云实证Vol.3:提速2920倍!用AutoDockVina对接2800万个分子》
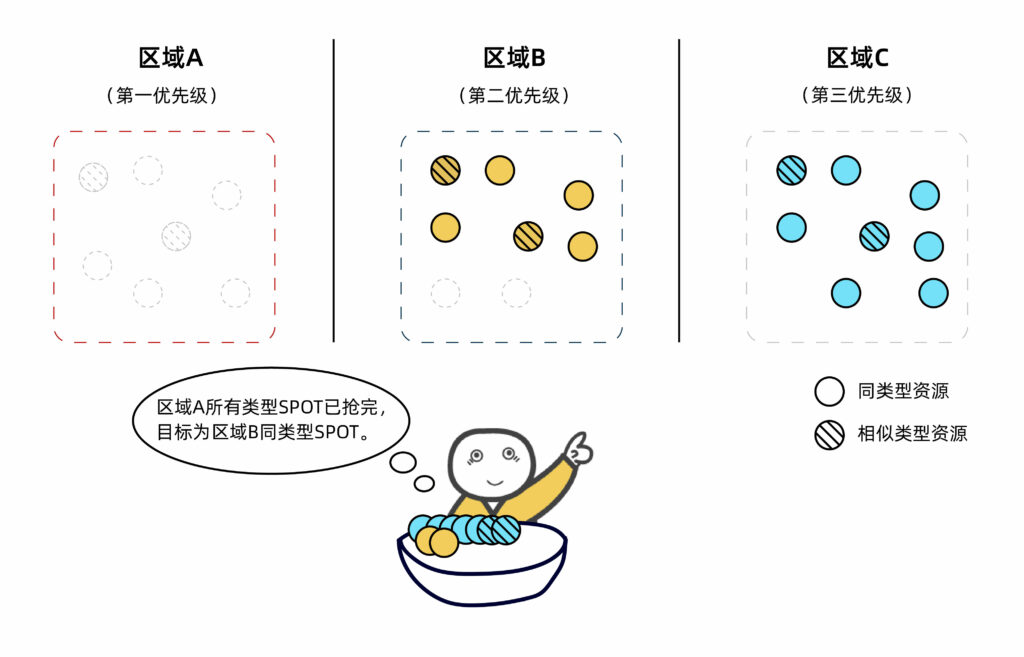
43、数据怎么做到云上、线下同步?
我们有专门的数据传输工具DM(Data Manager),让用户无需在多套认证系统之间切换,使用统一的身份认证即可传输数据,并自动关联云端集群进行计算,不改变其原有的使用习惯。
44、任务跑得怎么样可以在平台上监控吗?
提交任务后,可以在监控界面中查看任务和集群运行情况。
我们也可以在界面上查看任务运行的日志。
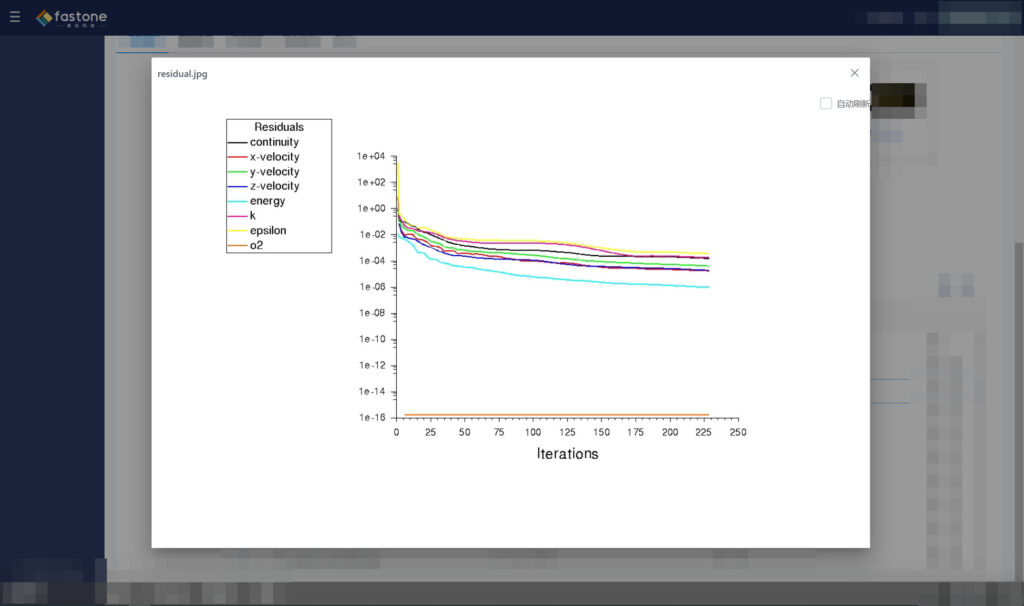
我们还支持实时查看任务本身的状态,比如Fluent的残差曲线,监控计算的收敛情况。
45、老师想搞深度学习,需要很多GPU,但有时候云上连几块GPU都很难抢到,怎么办?
一般来说单家云厂商的GPU可用资源是比较有限的,我们曾经在一个任务中成功地调用了155块NVIDIA Tesla V100,单个公有云厂商单区域资源未必能够随时满足这种需求。这里面就还涉及到跨云调度。
具体可以看《生信云实证Vol.6:155个GPU!多云场景下的Amber自由能计算》
46、我试过自己抢云厂商的SPOT,虽然确实很便宜,但非常难用,随时会断掉,你们对SPOT支持到什么程度?
由于SPOT一定会被抢走,我们的建议是用SPOT去算那些单个任务小总数却很多的东西。
比如生物/化学计算里的分子对接。常规分子对接任务几分钟即可算完,特别适合SPOT这种分分钟可能被抢走的状态。而且我们平台具备自动重试功能,一个任务被中断可以自动重新提交,任务之间互相不影响,重新提交单个任务影响很小。
四、你们跟超算比怎么样,有区别吗?
47、平时用超算经常排队用不到,你们说自己即开即用,难道你们的机器规模比超算还大?
确实比超算大,而且不在一个量级。
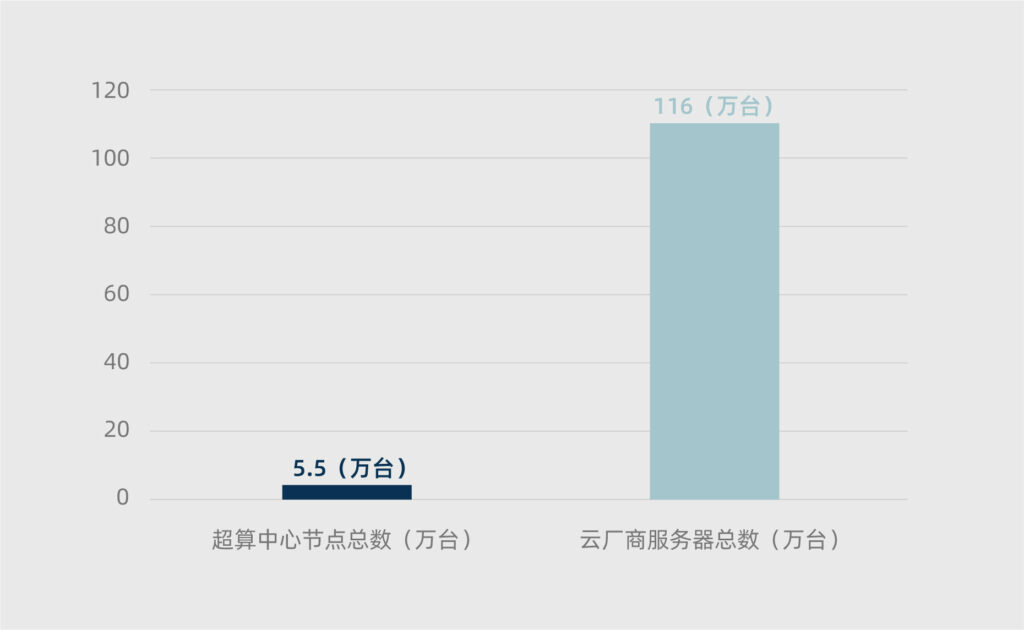
我们曾经盘点了中国已落成的主要超算中心的总节点数量,总数为54588个,其中未包括一些正在建设中的超算中心,以及小型超算中心。
即便加上这些数量,中国超算中心的总节点数量级也未过十万。
而根据IDC公布的中国公有云市场份额占比,阿里云以46.5万台服务器抢下了超过40%的市场份额,我们据此反推出国内云厂商的服务器总量超过116万台,超算中心与其完全不在一个数量级,可以看下图感受一下差距。
48、这么大规模的云资源,我们都能用吗?
短时间内可获取海量资源正是云资源特有的优势。
我们曾用AutoDock Vina上云,调用了十万核CPU资源做分子对接,详见《生信云实证Vol.3:提速2920倍!用AutoDock Vina对接2800万个分子》
49、GPU也一样能用吗?
可以,我们曾经在一个任务中调用了155块NVIDIA Tesla V100做Amber自由能计算,详见《生信云实证Vol.6:155个GPU!多云场景下的Amber自由能计算》
50、我们常用的超算中心机器配置比较固定,选择比较少,云上可以选吗?
云计算中心能够给用户提供更为丰富的计算资源选择。
如某公有云厂商的企业级云服务器分为通用型、计算型、内存型、大数据型、GPU型、本地SSD型、高主频型、FPGA型、弹性裸金属九大类,其中每一种类型还可以选择与不同存储和网络的组合,可根据需求自由选择。

51、你们支持的应用跟超算差不多吗?
我们支持所有主流科研应用,以及用户自编译的科研工具。
行业方向,除了生物/化学计算和CAE/CFD方向,还有集成电路设计EDA和AI框架。
52、不太懂IT,看到Linux就束手无策,我还能用你们这个云平台吗?
可以的,我们支持Windows系统。
另外,由于分布式计算场景大部分基于Linux系统,我们可为用户提供图形化界面,基本不改变操作习惯,通过简单的鼠标操作就可以跑任务,上手非常快。
53、怎么申请你们的资源?手续麻烦吗?周期要多久?
我们的云平台即开即用,3分钟即可使用,无需繁琐的申请流程。
而几乎每家超算中心都有一套申请、审核、使用流程,平均需要5.8个步骤。以国家超级计算天津中心为例,其步骤就多达8步。
54、我们学校的超算中心总是在用好多年前的旧机器,非常慢,实验室的情况稍微好一点,你们云上有新硬件吗?
你在云上随时可以用到最新的硬件。
举个例子,2019年4月3日上午,Intel在太平洋两岸近乎同步发布了代号Cascade Lake的第二代至强可扩展处理器。当天中午12点,国内某云厂商便宣布其基于Cascade Lake的全新一代通用计算增强型云服务器C6正式转为商用。
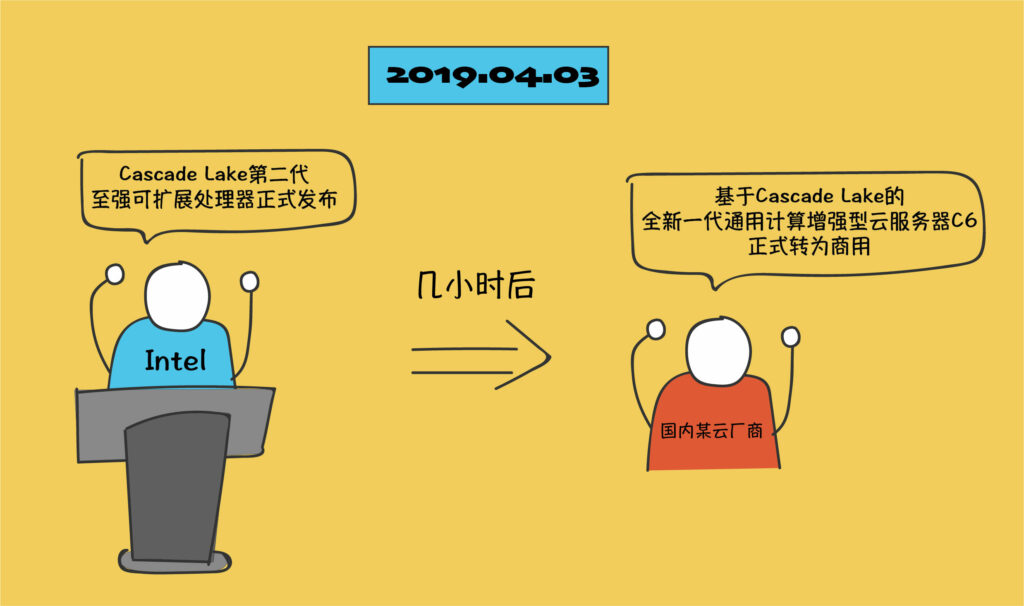
超算就要慢得多了,超算中心从规划设计到正式上线需要经历若干年的时间,能够在上线时配置当年上市的硬件已经是其规划能力的最佳体现,其最新硬件更新周期至少要以年为单位。
55、超算资源有时候跑着跑着就被强制回收了,你们也会有这种情况吗?
我们提供的是独占资源,不会被抢走。
56、我们之前用超算都是共享资源,不能改,也不能自己装一些组件,你们可以吗?
我们提供的是独占资源,用户拥有管理员权限,安装什么、如何使用均由用户自己做主。
57、用超算总感觉限制比较多,你们有什么限制吗?
我们的平台没有什么限制,连网即用。不但如此,我们提供的是一整套科研环境,详见第4问。
58、你们和超算还有什么区别?
具体可以看这篇《国内超算发展近40年,终于遇到了一个像样的对手》
本期的《这一届科研计算人赶DDL红宝书:学生篇》就到这里了。
在下一期《老师篇》中,我们将从老师视角和专业应用的角度出发,来看看高校计算云平台对科研工作所带来的帮助。
敬请期待哦~
- END -
我们有个科研计算云平台
集成多种科研应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送200元体验金,入股不亏~

更多电子书
欢迎扫码关注小F(ID:imfastone)获取

你也许想了解具体的落地场景:
Auto-Scale这支仙女棒如何大幅提升Virtuoso仿真效率?
1分钟告诉你用MOE模拟200000个分子要花多少钱
LS-DYNA求解效率深度测评 │ 六种规模,本地VS云端5种不同硬件配置
揭秘20000个VCS任务背后的“搬桌子”系列故事
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
关于为应用定义的云平台:
杨洋组织的“太空营救”中, 那2小时到底发生了什么?
速石科技获元禾璞华领投数千万美元B轮融资
一次搞懂速石科技三大产品:FCC、FCC-E、FCP
AI太笨了……暂时
速石科技成三星Foundry国内首家SAFE™云合作伙伴
Ansys最新CAE调研报告找到阻碍仿真效率提升的“元凶”,竟然是Ta……
【2021版】全球44家顶尖药企AI辅助药物研发行动白皮书
EDA云平台49问
国内超算发展近40年,终于遇到了一个像样的对手
帮助CXO解惑上云成本的迷思,看这篇就够了
花费4小时5500美元,速石科技跻身全球超算TOP500
收录于话题 #为应用定义的云35个下一篇缺人!缺钱!赶时间!初创IC设计公司如何“绝地求生”?






