LLM大语言模型的定义
大语言模型(英文:Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转化器,这有助于它们在各种NLP任务上取得令人印象深刻的表现。
LLM到底有多大?
拿 GPT 来说, GPT 其实出现了好几代,GPT 3 它有 45 个 Tb 的训练数据,那么整个维基百科里面的数据只相当于他训练数据的 0. 6%。我们在这个训练的时候把这个东西称作语料,就语言材料,这个语料的量是可以说是集中到我们人类所有语言文明的精华在里面,这是一个非常非常庞大的一个数据库。
从量变到质变
经过这样的一个量的学习之后,它产生的一些就是做 AI 的这些计算机学家们,他们没有想到会有这种变化,无法合理解释这一现象的产生即——当数据量超过某个临界点时,模型实现了显著的性能提升,并出现了小模型中不存在的能力,比如上下文学习(in-context learning)。
这也就催生了两个事件:
- 各大AI巨头提高训练参数量以期达到更好的效果
- 由于质变原因的无法解释带来的AI安全性考量
LLM涌现的能力
- 上下文学习。GPT-3 正式引入了上下文学习能力:假设语言模型已经提供了自然语言指令和多个任务描述,它可以通过完成输入文本的词序列来生成测试实例的预期输出,而无需额外的训练或梯度更新。
- 指令遵循。通过对自然语言描述(即指令)格式化的多任务数据集的混合进行微调,LLM 在微小的任务上表现良好,这些任务也以指令的形式所描述。这种能力下,指令调优使 LLM 能够在不使用显式样本的情况下通过理解任务指令来执行新任务,这可以大大提高泛化能力。
- 循序渐进的推理。对于小语言模型,通常很难解决涉及多个推理步骤的复杂任务,例如数学学科单词问题。同时,通过思维链推理策略,LLM 可以通过利用涉及中间推理步骤的 prompt 机制来解决此类任务得出最终答案。据推测,这种能力可能是通过代码训练获得的。
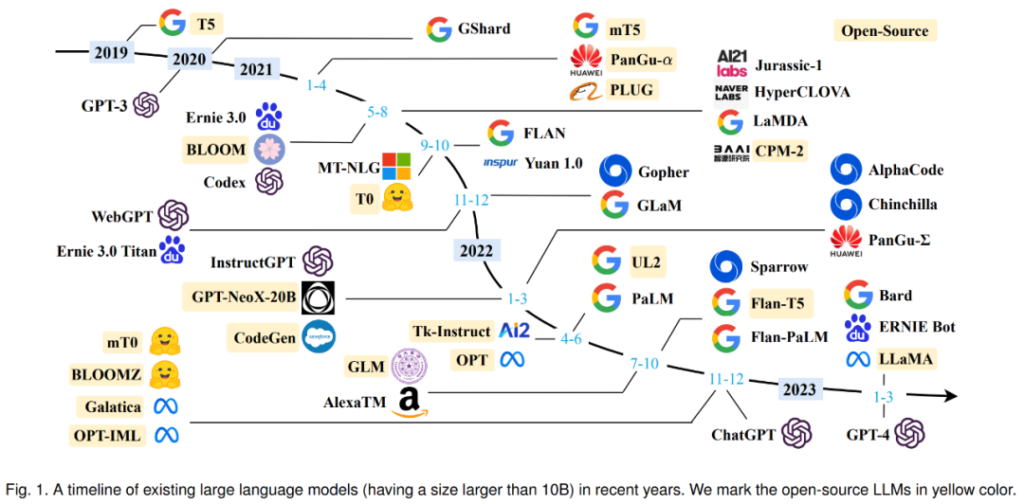
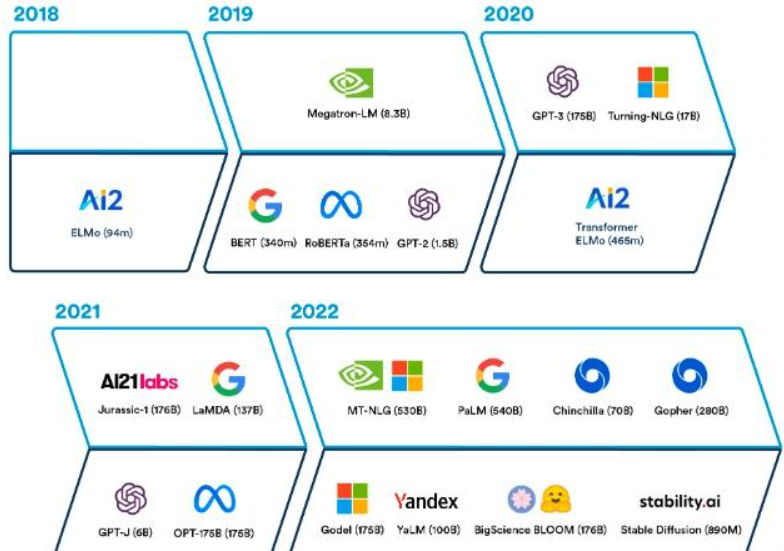
语言模型历史
2017谷歌推出 transformer 模型,2018 年的时候谷歌提出了 Bert 的模型,然后到 GPT 2,从 340 兆到 10 亿 、15 亿,然后到 83 亿,然后到 170 亿,然后到 GPT3 1750 亿的参数。
最早的是 2017 年出来的,就是我们所了解的那个GPT, GPT 名字里面有一个叫做transformer,就是这个 transformer 模型。它是 2017 年出现的,其实也很早,所以计算机领域来说, 2017 年可以归结于上一个时代的产品。然后 2018 年第一代 GPT 出来,当时还不行,相对来说比较差,性能也不行,然后像一个玩具一样。然后 2018 年谷歌又推出了一个新的模型,叫BERT,但是这些模型都是基于之前谷歌推出的这个 transformer 模型进行发展的。然后到了 2019 年, open AI 除了 GPT 2 也没有什么特别,就是它没有办法来产生一个语言逻辑流畅通顺的一段名词,你一看就知道这是机器写的。
但是到了 2020 年的5月, GPT 3 出来之后,其实就有了非常大的变化, GPT 3 的性能比 GPT 2 好很多,它的数参数的数量级大概是 GPT 2- 10 倍以上。
LLM的训练方式
训练语言模型需要向其提供大量的文本数据,模型利用这些数据来学习人类语言的结构、语法和语义。这个过程通常是通过无监督学习完成的,使用一种叫做自我监督学习的技术。在自我监督学习中,模型通过预测序列中的下一个词或标记,为输入的数据生成自己的标签,并给出之前的词。
训练过程包括两个主要步骤:预训练(pre-training)和微调(fine-tuning):
- 在预训练阶段,模型从一个巨大的、多样化的数据集中学习,通常包含来自不同来源的数十亿词汇,如网站、书籍和文章。这个阶段允许模型学习一般的语言模式和表征。
- 在微调阶段,模型在与目标任务或领域相关的更具体、更小的数据集上进一步训练。这有助于模型微调其理解,并适应任务的特殊要求。
常见的大语言模型
GPT-3(OpenAI): Generative Pre-trained Transformer 3(GPT-3)是最著名的LLM之一,拥有1750亿个参数。该模型在文本生成、翻译和其他任务中表现出显著的性能,在全球范围内引起了热烈的反响,目前OpenAI已经迭代到了GPT-4版本
BERT(谷歌):Bidirectional Encoder Representations from Transformers(BERT)是另一个流行的LLM,对NLP研究产生了重大影响。该模型使用双向方法从一个词的左右两边捕捉上下文,使得各种任务的性能提高,如情感分析和命名实体识别。
T5(谷歌): 文本到文本转换器(T5)是一个LLM,该模型将所有的NLP任务限定为文本到文本问题,简化了模型适应不同任务的过程。T5在总结、翻译和问题回答等任务中表现出强大的性能。
ERNIE 3.0 文心大模型(百度):百度推出的大语言模型ERNIE 3.0首次在百亿级和千亿级预训练模型中引入大规模知识图谱,提出了海量无监督文本与大规模知识图谱的平行预训练方法。
速石科技AI应用
AI应用落地是所有研发环节中最后一环,也是最重要的一环。在AIGC应用百花齐放的这波浪潮中,速石科技作为MLOps平台的提供方,同时也是其使用方。
速石科技已经发布一款行业知识库聊天应用Megrez,这款聊天应用面向企业客户提供大语言模型的私有化部署能力,解决了许多企业用户关注的数据安全问题,它也允许用户自定义行业知识库,实现领域知识的问答。
更多可查看:速石科技应邀出席2023世界人工智能大会,AI研发平台引人瞩目
本文转载:https://zhuanlan.zhihu.com/p/622518771
- END -
我们有个AI研发云平台
集成多种AI应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送200元体验金,入股不亏~

更多电子书欢迎扫码关注小F(ID:iamfastone)获取
你也许想了解具体的落地场景:
王者带飞LeDock!开箱即用&一键定位分子库+全流程自动化,3.5小时完成20万分子对接
这样跑COMSOL,是不是就可以发Nature了
Auto-Scale这支仙女棒如何大幅提升Virtuoso仿真效率?
1分钟告诉你用MOE模拟200000个分子要花多少钱
LS-DYNA求解效率深度测评 │ 六种规模,本地VS云端5种不同硬件配置
揭秘20000个VCS任务背后的“搬桌子”系列故事
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
关于为应用定义的云平台:
当仿真外包成为过气网红后…
和28家业界大佬排排坐是一种怎样的体验?
这一届科研计算人赶DDL红宝书:学生篇
杨洋组织的“太空营救”中, 那2小时到底发生了什么?
一次搞懂速石科技三大产品:FCC、FCC-E、FCP
Ansys最新CAE调研报告找到阻碍仿真效率提升的“元凶”
国内超算发展近40年,终于遇到了一个像样的对手
帮助CXO解惑上云成本的迷思,看这篇就够了
花费4小时5500美元,速石科技跻身全球超算TOP500