

本篇来说下CADD对药物设计领域产生了重大影响。此外,CADD与人工智能(AI)、机器学习(ML)和深度学习(DL)技术相结合,处理大量生物数据,减少了与药物开发过程相关的时间和成本。
1.概述
计算机辅助药物设计(CADD)结合了各种计算机工具,以识别和开发有前途的lead。CADD包括计算化学、分子建模、分子设计和合理的药物设计。在当今的大数据环境中,访问大量数据并不能保证获得适用的预测模型。为了预测治疗效果和副作用,必须开发系统地解决大量、多维和稀疏数据源的技术。
1.1 计算机辅助药物设计
CADD基于蛋白质或配体的3D结构的可用性,利用两种不同的技术进行药物发现:基于结构的药物设计(SBDD)和基于配体的药物设计(LBDD)(图1)。在某些情况下,两种技术的整合在查找先导分子方面显示出良好的准确性。
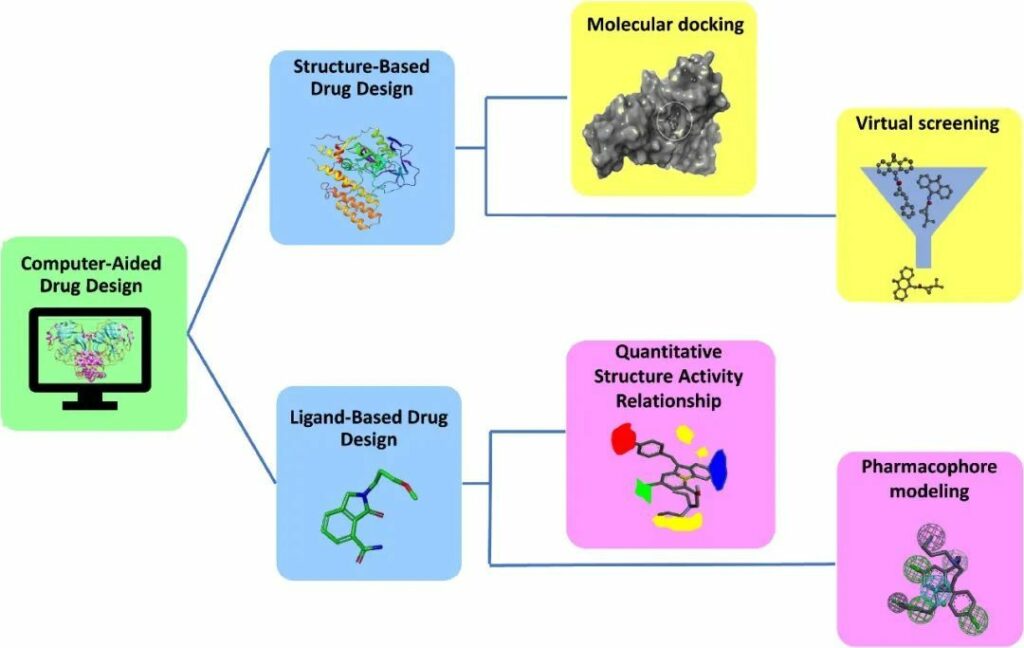
图1 -CADD概览
1.1.1 SBDD
基于结构的药物设计(SBDD):随着越来越多生物分子的三维结构的公开,SBDD在药物发现和设计方面的新时代已经开始。SBDD已成为制药行业中生成和优化配体的可能手段。靶标的识别、结合位点的鉴定、分子对接、虚拟筛选和分子动力学是SBDD的基本步骤。
1.1.1.1靶标准备
准备靶点大分子结构是SBDD中最关键的一步。由于X射线和NMR结构解析技术的快速发展,沉积在蛋白质数据库(PDB)中的蛋白质的3D结构很容易获得。当目标蛋白的三维结构不可用时,计算方法,如比较或同源建模(comparative or homology modeling)、threading和ab initio已经能成功地从蛋白质的序列中确定其结构。
同源建模或比较建模:可以使用各种计算结构预测技术(包括同源性建模)从其氨基酸序列推断蛋白质3D结构(表1)。它被认为是精度最高的计算结构预测方法。其中有几个简单且易于遵循的步骤:寻找具有相似序列的结构模板蛋白,对齐它们的序列,使用对齐的区域坐标,预测目标缺失的原子坐标,模型构建和细化。NCBI基本局部比对搜索工具(BLAST)是用于序列相似性搜索的最广泛使用的生物信息学序列比对工具之一。
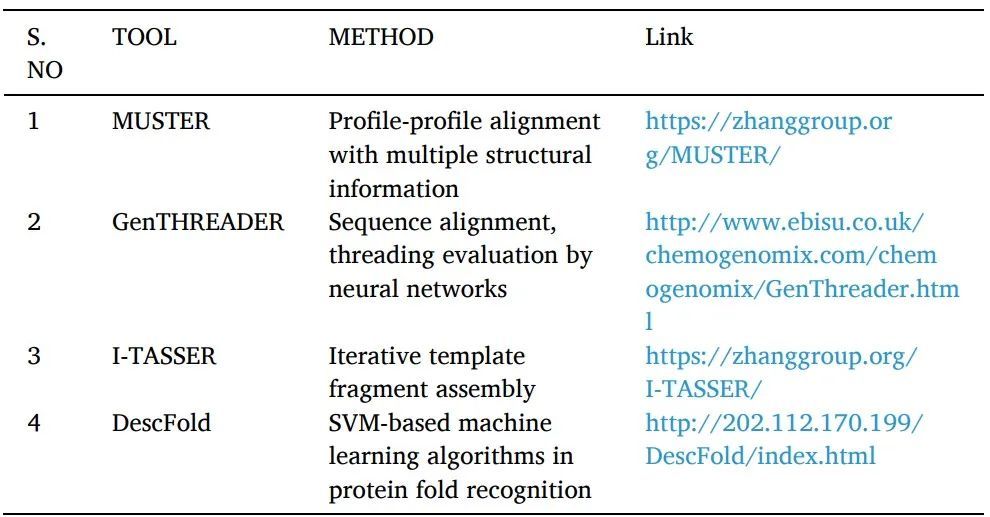
Fold recognition or threading:用于寻找具有可比折叠但没有序列相似性的蛋白质。一个已知的蛋白质结构的序列被感兴趣的目标的查询序列所取代,对于该结构是未知的。然后用各种评分系统对产生的"threaded"结构进行评估。对每个数据库的经验确定的三维结构重复这一过程,提供与查询序列最匹配的结构(表2)。它被运用于SBDD研究中。
表2 threading方法工具
从头或从头建模:当结构中没有足够的同质性来进行比较建模时,将执行从头或从头建模(表3)。
表3 用于从头建模的工具

1.1.1.2活性结合位点的鉴定和表征
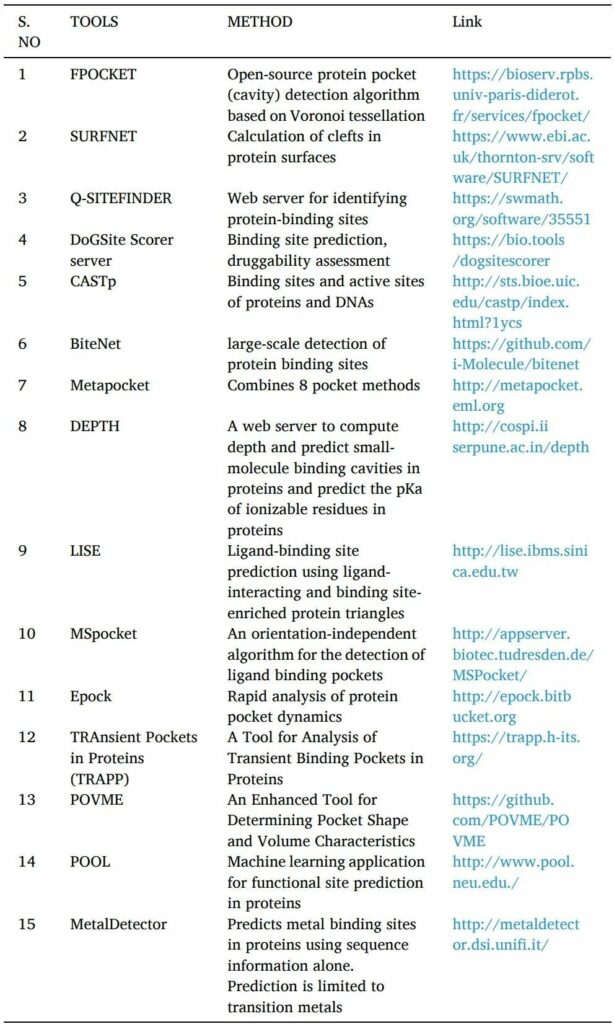
药物活性需要蛋白质和配体的相互作用。只有找到高亲和力结合位点才有可能。在基于结构的药物发现方法中开发新方法在很大程度上取决于识别靶蛋白上的可药腔或口袋。
POCKET,SURFNET,Q-SITE FINDER,DoGSite Scorer server,CASTp,NSiteMatch,metapocket等工具是用于预测靶点蛋白结合位点的计算机工具。
找到结合位点后,使用诸如Epock,TRAPP和POVME等工具或服务器来确定结合口袋的体积(表4)。
1.1.1.3 分子对接
表4 结合位点预测工具
分子对接是一种用于确定配体分子在大分子靶标结合位点中的构象和取向(统称为“位置”)的技术。
搜索算法用于生成姿势,然后使用评分技术进行排名。许多生物过程,如信号传递、细胞控制和其他大分子组装,依赖于分子识别,如酶-底物、药物-蛋白质、药物-核酸、蛋白质-核酸和蛋白质-蛋白质相互作用。采样和评分是蛋白质-配体对接方法的两个关键组成部分。
配体采样和蛋白质灵活性是采样的两个方面,指的是在蛋白质结合位点附近创建可能的配体结合方向/构象。评分使用物理方法或经验预测单个配体取向/构象的结合紧密性。
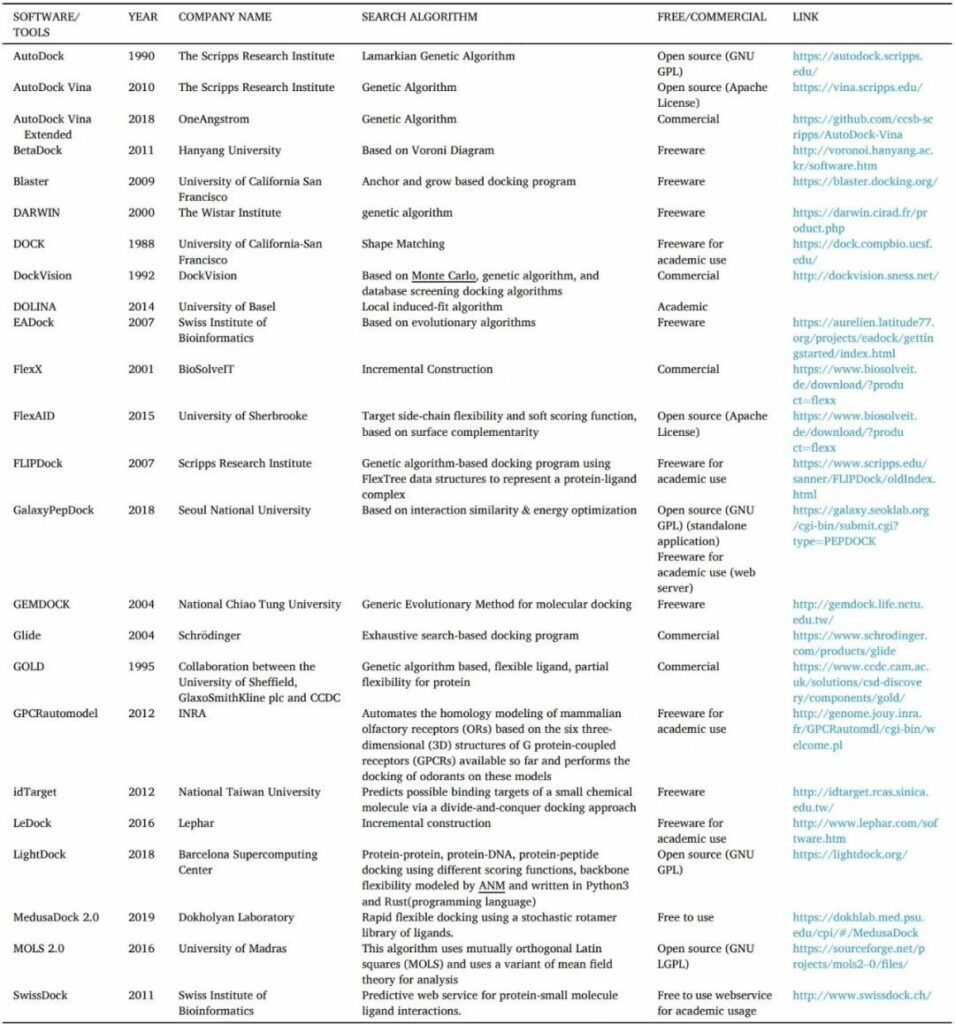
表5 对接工具/软件的清单
蛋白质-配体对接的分类方法有几种。
根据蛋白质灵活性,方法分为四类:
软对接:在对接模拟中,它放松了原子间Vander Waals接触,允许配体和蛋白质之间略有重叠。
侧链灵活性:早期的研究之一是Leach的配体对接方法,该方法使用旋转体库来结合离散的侧链灵活性。从那时起,已经提出了一系列新技术,用于在配体对接中添加连续或离散的侧链灵活性。
分子弛豫:第三种方法考虑蛋白质的柔韧性,通过使用刚体对接将配体引入结合位点,然后松弛蛋白质主链和附近的侧链原子。初始刚体对接允许蛋白质和插入的配体取向/构象之间的原子冲突,以适应蛋白质构象差异。使用蒙特卡罗(MC)模拟,分子动力学模拟或其他方法松弛或最小化复合物。
蛋白质集合对接:添加蛋白质柔韧性的最广泛使用的方法涉及蛋白质结构的集合,以反映各种构象变化。
根据配体采样,方法分为两类:
有两种配体采样算法:系统搜索和随机算法(表6)。
表6使用随机或系统搜索算法的软件/工具
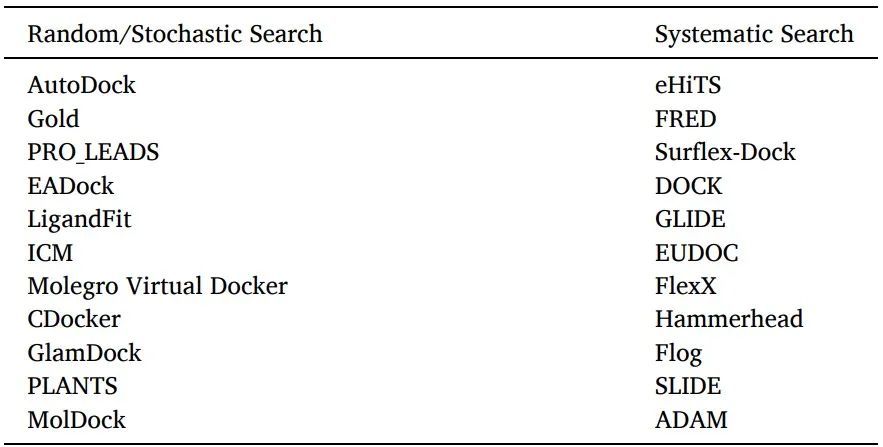
系统搜索:对于灵活的配体对接,通常使用系统搜索技术,通过探索配体的所有自由度来创建所有潜在的配体结合构象。
随机算法:通过在构象空间和配体的平移/旋转空间的每一步对配体进行随机修改,在随机算法中对配体结合取向和构象进行采样。
根据评分功能,方法分为三类:
对接分数是基于评估复合体能量亲和力的评分函数的计算。这些评分函数可以在分子力学、经验数据、专业知识或共识库上找到。共识评分(Consensus scoring)是一种通过组合几种评分算法的结果来预测化合物对特定靶标的结合亲和力的方法。根据推导方法分为三个基本类别:基于力场、基于经验和基于知识的评分函数。
力场(FF)评分函数:基于配体结合能分解为单个相互作用项,例如范德华(VDW)能量,静电能,键拉伸/弯曲/扭转能等,使用一组派生的力场参数,例如AMBER或CHARMM力场。
经验评分函数:配合物的结合能得分是通过将几个加权经验能项(如VDW能,静电能,氢键能,脱溶剂化项,熵项,疏水性项等)相加得出。
基于知识的评分函数:直接从实验确定的蛋白质配体复合物中的结构信息生成平均力的电位,由玻尔兹曼反比关系描述为基于知识的评分函数提供基础。
1.1.1.4 虚拟筛选(VS)
在计算机中,从化学数据库中选择有希望的化合物的方法被称为虚拟筛选,并且可以被认为是实验生物学评估方法的计算机化等效物,如高通量筛选(HTS)。
VS分为两类:(i)基于结构的虚拟筛选(SBVS)和(ii)基于配体的虚拟筛选(LBVS)(图2)。
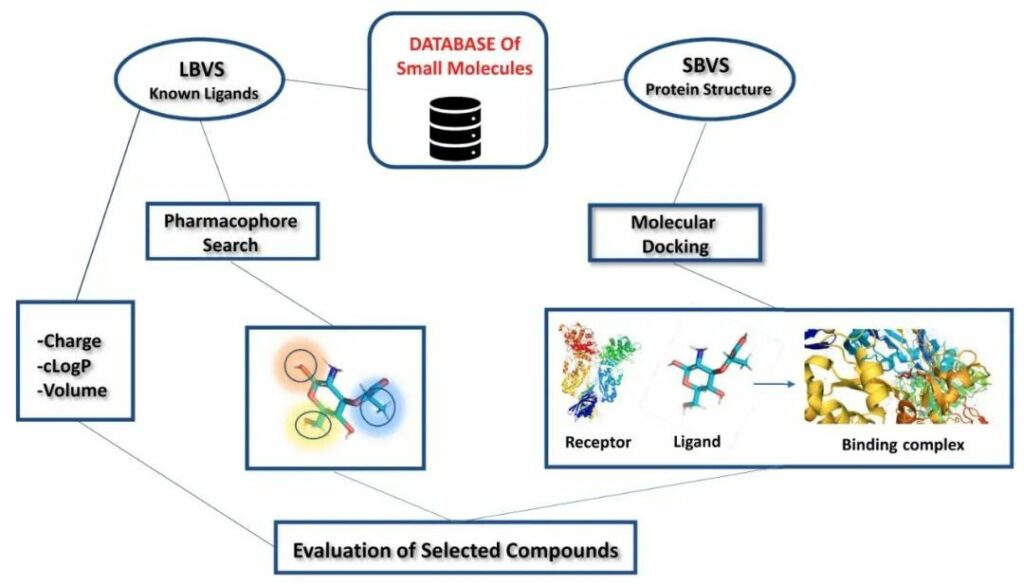
图2 基于结构和基于配体的虚拟筛选概述
基于结构的虚拟筛选(SBVS):这是一种基于计算机的方法,用于在早期药物开发项目中针对特定治疗靶点搜索化合物库中的新型生物活性化合物。SBVS中的化合物数据库停靠在预定的靶标结合位点。除了预测结合模式外,SBVS还为对接的分子分配排名。该评级可以用作选择有前途的分子的唯一标准,也可以与其他评估方法结合使用。进行实验以确定所研究分子靶标上指示药物的生物活性。SBVS包括四个步骤:(i)分子靶标准备(ii)化合物数据库选择(iii)分子对接和(iv)对接后分析。
表7 用于以图形方式显示SBVS和分子对接结果的程序
基于配体的虚拟筛选(LBVS):通过采用称为基于配体的虚拟筛选的计算技术,可以根据有效结合到靶标的配体的信息生成靶蛋白的模型。之后,使用该模型预测新配体与靶标结合的可能性。LBVS是唯一没有靶蛋白3D结构的方法。LBVS试图使用已知的活性化学物质作为输入信息来识别具有相似属性的结构多样化的分子。
1.1.1.5 分子动力学(MD)模拟
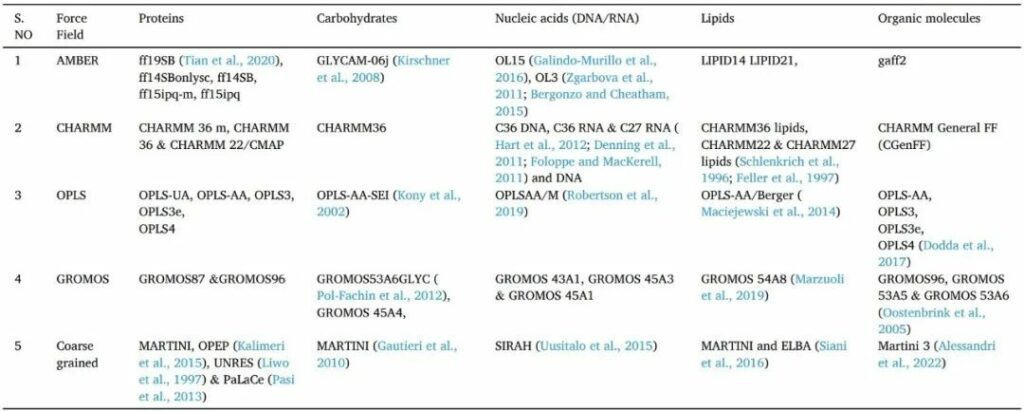
这种复杂的物理技术基于牛顿引导原子间相互作用的运动方程。它用于预测分子系统中每个原子相对于时间的位置。分子动力学(MD)模拟对于研究蛋白质行为至关重要。在MD模拟中,化学键和键角使用简单的虚拟弹簧描绘,而二面角则使用正弦函数处理。GPU 最初设计用于加速视频游戏,现在正用于显着加速分子动力学模拟。分子力学泊松-玻尔兹曼表面积(MM / PBSA),线性相互作用能(LIE)(和自由能扰动方法(FEP)是用于自由能计算的一些MD应用,以关联实验和计算的小分子与蛋白质的结合亲和力。分子动力学模拟可以使用牛顿物理学和力场(如Amber或CHARMM OPLS,GROMOS和粗粒度力场(表8)计算构象轨迹作为时间的函数。
表8 MD仿真中使用的力场列表
AMBER(具有能量细化的辅助模型构建):AMBER是一组分子模拟程序和一组用于模拟生物分子的分子机械力场。Peter Kollman的小组在1970年代后期在加州大学旧金山分校开发了这种方法,以研究各种分子,如蛋白质,DNA,RNA,碳水化合物,有机分子,蛋白质模拟物,脂质和氟化芳香族氨基酸。为了施加分子对称性,在全原子原子辅助模型构建与能量细化(AMBER)系列力场中,部分电荷被分配具有静电表面电位。
CHARMM(哈佛大学大分子力学化学):CHARMM程序最初由哈佛大学的Martin Karplus教授小组开发,该小组协调经验力场参数化的努力。它具有针对各种分子参数化的特定力场。CHARMM力场中的部分电荷通常适合从头计算的尺度能量。
OPLS(液体模拟的优化电位):与实验结果相比,OPLS力场在预测蒙特卡罗模拟获得的结构和热力学特性方面表现出准确性。
OPLS-AA力场,用于重现小分子的量子力学构象能量分布。此外,它还从AMBER中获得了几个粘结参数。
GROMOS(格罗宁根分子模拟):GROMOS是一种用于研究生物分子系统的分子动力学的多用途计算机模拟工具。它还具有内置力场,包括蛋白质、核苷酸、糖和其他分子。它可用于模拟各种化学和物理系统,包括玻璃、液晶、聚合物、晶体和生物分子溶液。
粗粒度力场(CG):CG力场通过减少模型中的自由度数来降低计算的计算成本,从而允许对更大的系统进行更长时间的仿真。粗粒度(CG)模型有两种常规方法:自下而上和自上而下。许多化合物的极性相和非极性相之间的自由能分配是CGMartini力场的基础。Martini力场也是与原子模型密切合作开发的,特别是在束缚相互作用方面。
1.1.2 LBDD
在没有关于受体的3D信息的情况下,可使用基于配体的药物设计。该技术依赖于与感兴趣的生物靶标结合的分子知识。
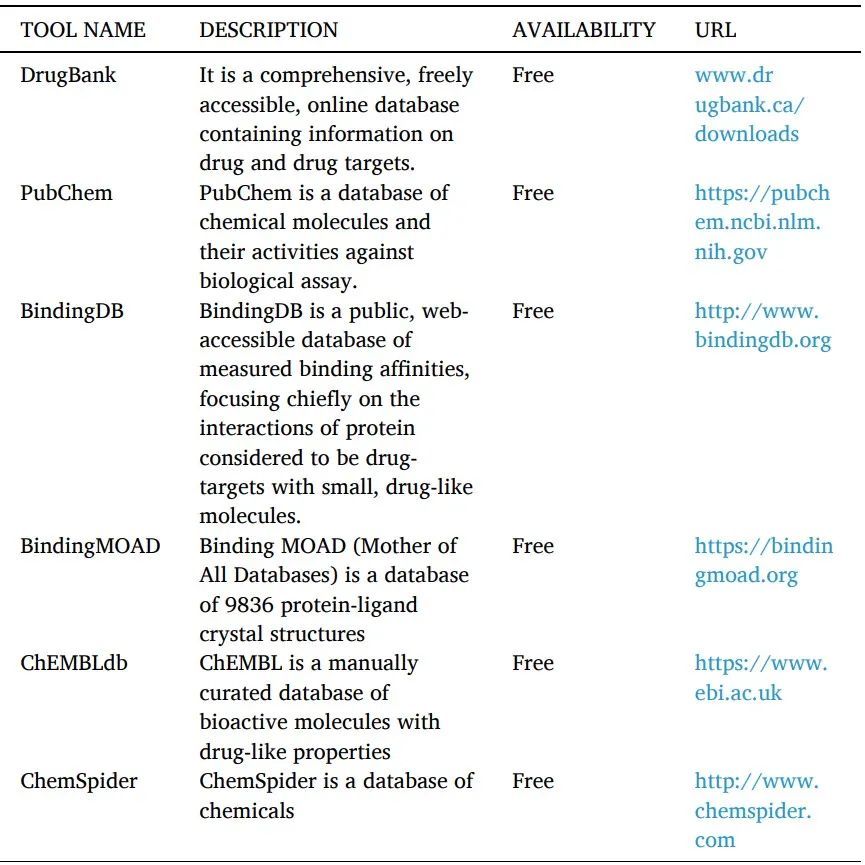
与靶标结合的已知配体的化学指纹图谱用于分子相似性方法,以使用分子库进行筛选来鉴定具有相似指纹的化合物(表9)。配体相似性搜索方法是有效的,因为结构相关的化合物具有相当的结合特性。
表9 小分子数据库
QSAR和药效团是LBDD的两种方法。
1.1.2.1 QSAR
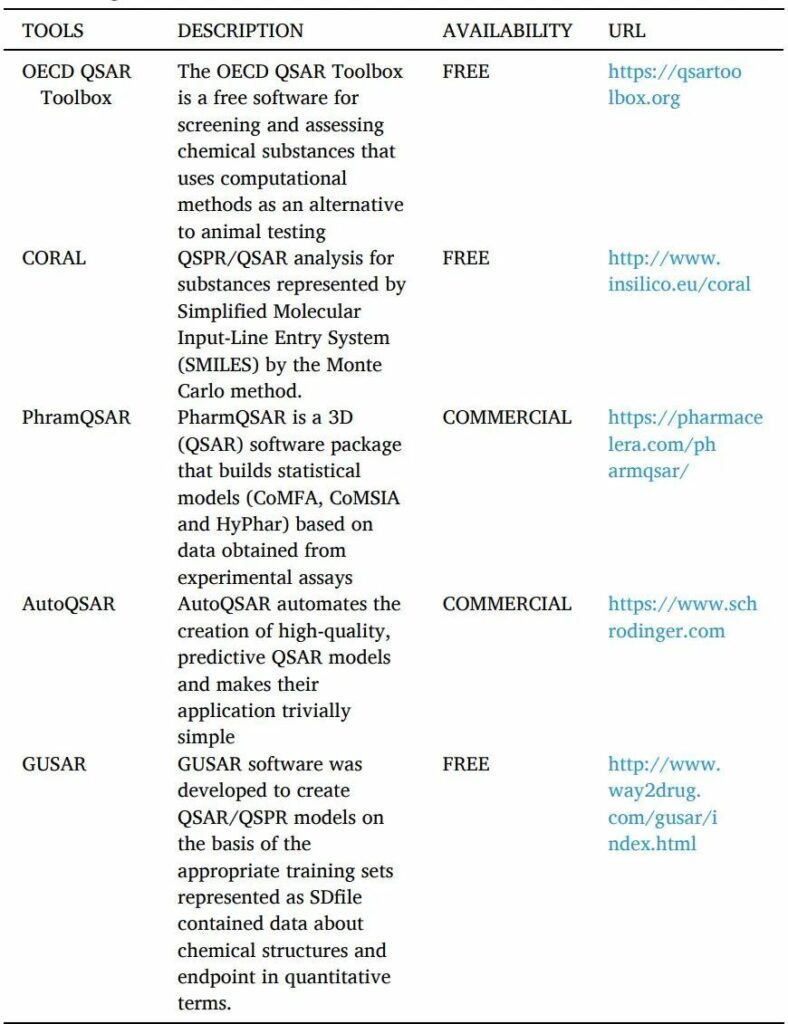
QSAR是一种计算机化的统计工具,用于解释观察到的由替换产生的结构变化(表10)。这些模型用数学方法证明配体的结构特性如何影响与之结合的靶点的活性反应。可用于建立QSAR模型的分子参数可能包括电子、疏水、立体和亚结构效应。
QSAR的工具如下。
表10 QSAR工具
详细参数:
电子效果:电离常数、Σ取代基常数、分布常数、共振效应、场效应、分子轨道指数、原子/电子净电荷、亲核超离域性、亲电超离域性、自由基超离域性、最低空分子轨道和最高占据分子轨道的能量、前沿原子-原子极化率、分子间库仑相互作用能、由一组电荷在点(A)处产生的电场分子。
疏水参数:分配系数、Pi取代基常数、液-液色谱中的Rm值、高压液相色谱(HPLC)中的洗脱时间、溶解度、溶剂分配系数。
空间效应:分子内空间位阻效应、空间位阻取代基常数、超共轭校正、摩尔体积、摩尔折射率、MR 取代基常数、分子量、范德华半径原子间距离。
子结构效应:三维几何碎片和分子性质。
QSAR的步骤(图3)如下:
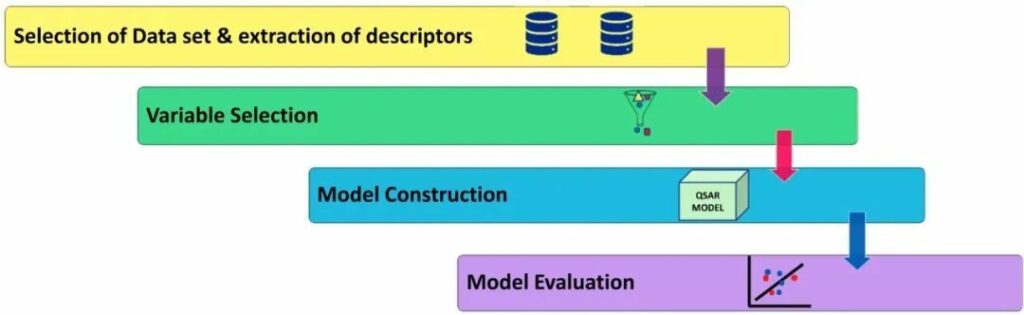
制备用于QSAR实验的分子:获得一组在类似生物学测定中测试并显示出广泛作用的同属配体。
训练集中描述符的选择:识别并确定与化合物理化性质相关的分子描述符。
计算训练集中描述符的值:将分子随机分为两组:训练集和测试集。使用训练集,识别并计算可以解释描述符值与生物活性之间关系的相关系数。
内部和外部验证评估:使用测试集分子,评估统计方法的稳定性。
1.1.2.2 药效团建模
根据IUPAC的定义,药效团是“实现与给定生物靶标的最佳超分子相互作用并触发或预防其生物反应所需的空间位阻和电子特性的集合”。药效团是对生物大分子识别配体所需结构特性的抽象描述(表11)。
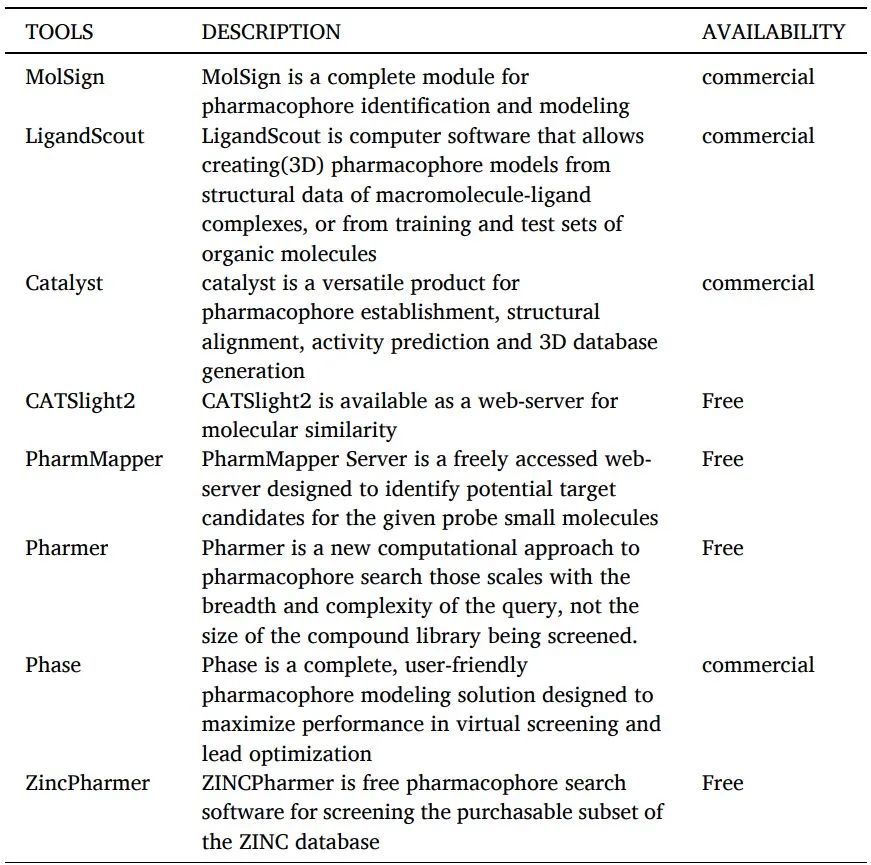
药效团建模工具如下。
表11 药效团建模工具
药效团建模中涉及的步骤(图4)如下:
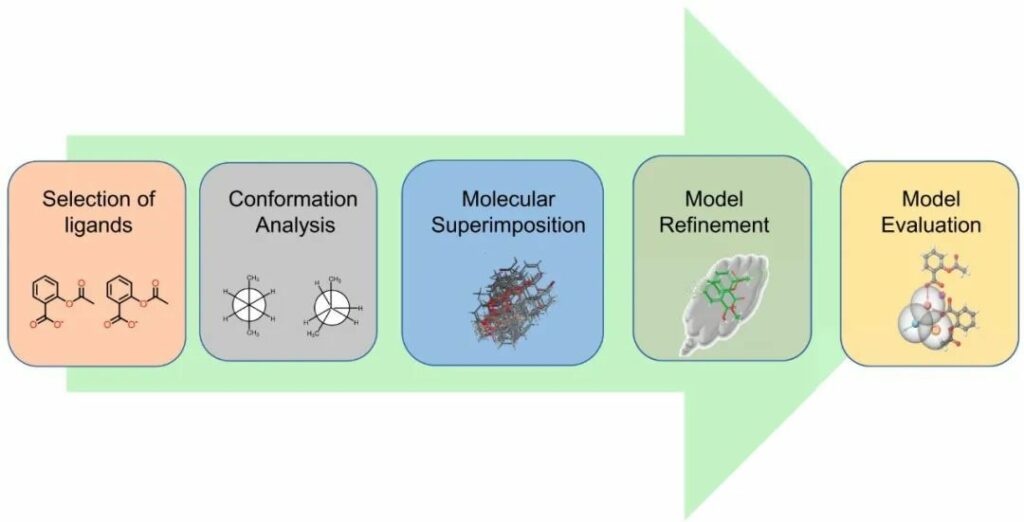
图4 药效团建模中涉及的步骤
选择一组训练配体:对于药效团模型开发,请选择结构多样化的化合物组。分子列表应包括活性和非活性化合物,因为药效团模型必须能够区分具有和没有生物活性的分子。
构象分析:为每种选定化合物创建一个低能量构象列表,其中可能包括生物活性构象。
分子叠加:叠加分子低能构象的所有可能组合。可以拟合集合中所有分子中相似的官能团(例如,苯基环或羧酸基团)。假定活性构象是导致最佳拟合的构象集合。
抽象:创建叠加分子的抽象表示。例如,叠加的苯基环在更概念的意义上可以称为“芳香环”药效团元素。
验证:药效团模型是一种假设,用于解释与同一生物靶标结合的一组化合物的药理作用。
1.2 药物设计和药物发现中的人工智能
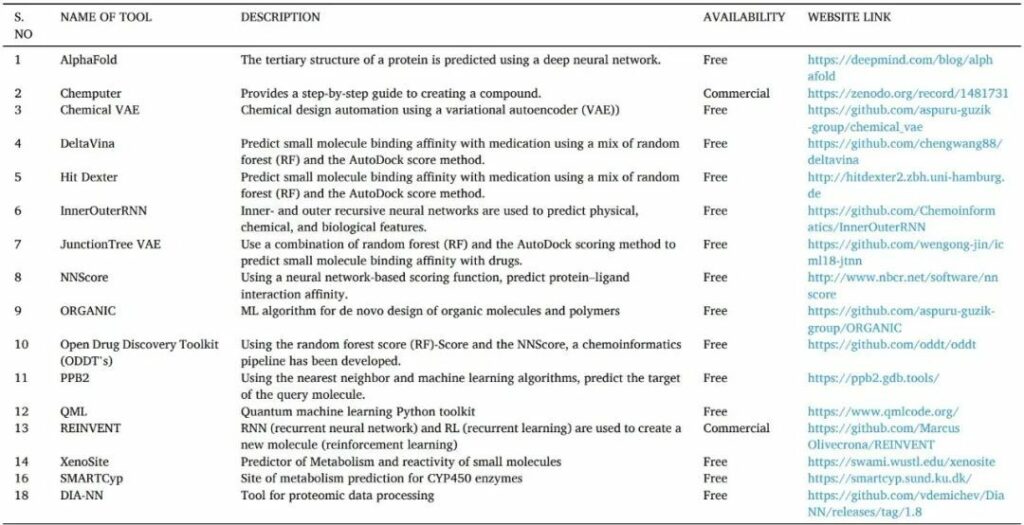
人工智能是通过机器或计算机对人类智能的模拟。它们通常通过训练大量预先训练的模型,分析相关性和模式的信息,然后使用这些模式进行预测来工作。人工智能可以识别hit和先导化合物,更快地验证药物靶标,并优化药物结构设计。它还可以帮助靶向蛋白质的 3D 结构预测、蛋白质-蛋白质相互作用、药物活性和从头药物设计(表13)。
表13 用于药物发现的人工智能工具
2 结论
上述CADD技术被广泛认为在所有情况下都远非完美和无所不能。为了有效地采用当前的计算方法,必须克服相当大的限制。人工智能、机器学习和深度学习方法可以与基本的CADD程序一起使用,以提供更准确和准确的结果。
本文详细解释了到目前为止计算工具和技术是如何应用于药物发现和开发的。还描述了药物发现和开发过程中使用的当前工具和软件列表。
- END -
我们有个生物/化学计算云平台
集成多种CAE/CFD应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送200元体验金,入股不亏~

更多电子书 欢迎扫码关注小F(ID:imfastone)获取

你也许想了解具体的落地场景:
这样跑COMSOL,是不是就可以发Nature了
Auto-Scale这支仙女棒如何大幅提升Virtuoso仿真效率?
1分钟告诉你用MOE模拟200000个分子要花多少钱
LS-DYNA求解效率深度测评 │ 六种规模,本地VS云端5种不同硬件配置
揭秘20000个VCS任务背后的“搬桌子”系列故事
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
关于为应用定义的云平台:
Uni-FEP on fastone|速石科技携手深势科技,助力创新药物研发提速
【2021版】全球44家顶尖药企AI辅助药物研发行动白皮书
创新药研发九死一生,CADD/AIDD是答案吗?
这一届科研计算人赶DDL红宝书:学生篇
AI太笨了……暂时
帮助CXO解惑上云成本的迷思,看这篇就够了
国内超算发展近40年,终于遇到了一个像样的对手
花费4小时5500美元,速石科技跻身全球超算TOP500
【大白话】带你一次搞懂速石科技三大产品:FCC、FCC-E、FCP






