"结构就是功能"——蛋白质的工作原理和作用取决于其3D形状。
2020年末,基于深度神经网络的AlphaFold2,一举破解了困扰生物学界长达五十年之久的“蛋白质折叠”难题,改变了科学研究的游戏规则,可以从蛋白质序列直接预测蛋白质结构,实现了计算机蛋白质建模极高的精确度。
自AF2问世以来,全世界数百万研究者已经在疟疾疫苗、癌症治疗和酶设计等诸多领域取得了突破。
2024年5月初,AlphaFold3再登Nature,基于Diffusion(扩散技术)架构,将技术延伸到蛋白质折叠之外,能以原子级精度准确预测蛋白质、DNA、RNA、配体等生命分子的结构及相互作用。
为了避免Diffusion技术在一些无结构区域产生“幻觉”,DeepMind还创新了一种交叉蒸馏(cross-distillation)方法,把AF2预测的结构数据预添加到AF3的预训练集中,减少AF3的预测失误。
AF2代码已开源,AF3目测不会开源,也不能商用。
我们今天的主角——只能是AlphaFold2。
想知道怎么使用AlphaFold2最最快乐?
怎么快速完成蛋白质结构预测任务?
我们能在背后帮你默默干点什么?
来吧——
01
先复习一下
AlphaFold2计算的正确打开方式
我们通常说的AlphaFold2是指一个利用多个外部开源程序和数据库,通过蛋白质序列预测其3D结构的系统。
整个蛋白质结构预测计算过程大致可以分为两个阶段:
一、数据预处理
包括多序列比对(MSA)和模板搜索(Template Search)两个步骤,主要是利用已知的蛋白质序列和结构模板,获得不同蛋白质之间的共有进化信息来提升目标蛋白质结构预测的准确性。
需要比对和搜索的数据总和达到了TB量级,涉及数据库密集I/O读写,因此对I/O有较高的要求。
这一阶段主要使用HMMER与HH-suite软件,以及Uniprot、MGnify、PDB等多个蛋白质数据库。计算耗时与蛋白序列长度正相关,主要使用CPU计算资源。
AF2训练数据集覆盖多个数据库,比如UniRef90/MGnify/PDB/BFD等,目前完整版大小约为2.62TB,是世界范围内较为权威的蛋白质三维结构数据库。2022年7月28日,Google DeepMind将数据库从近100万个结构扩展到超过2亿个结构,涵盖了植物、细菌、动物和其他微生物等多个类别。
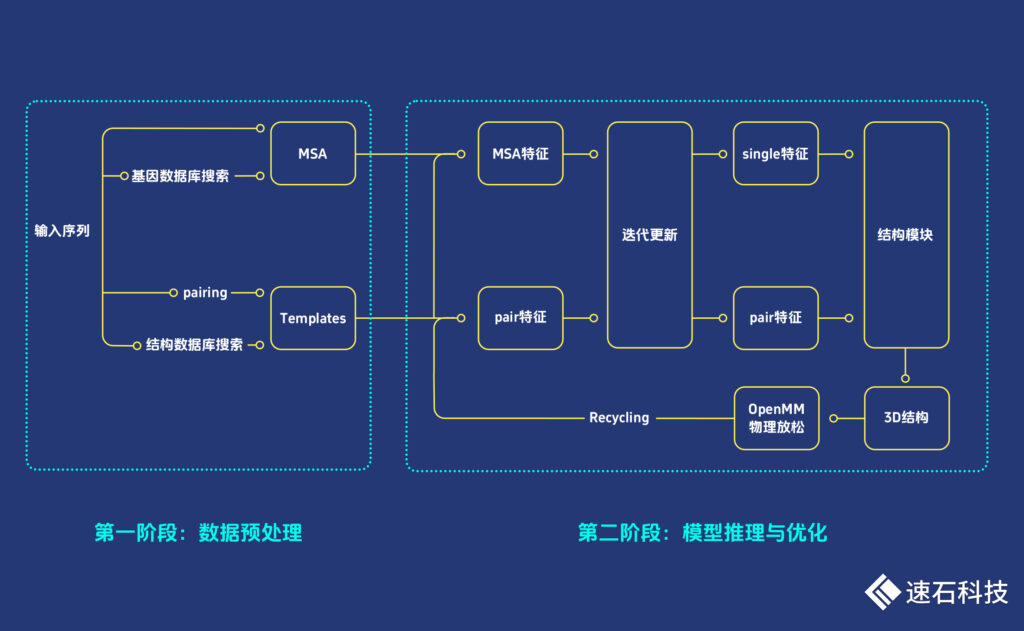
二 、模型推理与优化
基于端到端的Transformer神经网络模型,AF2输入Templates、MSA序列和pairing信息,其中pairing和MSA信息相互迭代更新,检测蛋白质中氨基酸之间相互作用的模式,输出基于它们的3D结构。
再用OpenMM软件对预测的3D结构进行物理放松,解决结构违规与冲突。
使用Recycling(将输出重新加入到输入再重复refinement)进行多轮迭代训练和测试,多轮迭代优化有一定的必要性,较为复杂的蛋白可能在多轮之后才能折叠到正确的结构。
这一阶段计算耗时与迭代次数正相关,主要使用GPU计算资源。
02
Workflow全流程自动化
随心组合,当一个甩手掌柜
作为一个系统,AlphaFold2借助了多个外部开源软件和数据库,整个计算过程也比较复杂。
如果用户想要自行使用,不但要下载庞大的数据库,还需要自行搭建使用环境,对IT能力的要求不可谓不高。
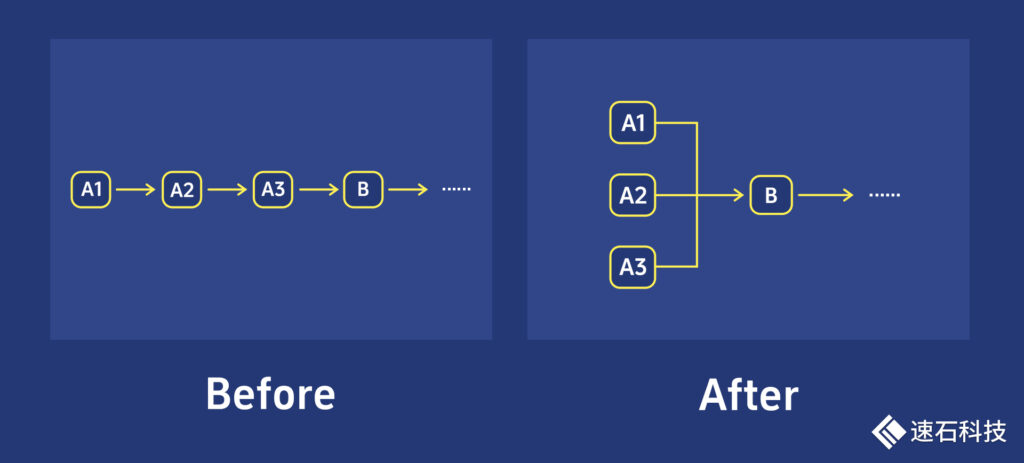
用户看到的基本都是左边这种画面,我们能做的第一点——就是提供一个平台,把左边变成右边:

而第二点,我们能跨越系统各个软件之间,包括对软件内部的不同步骤任意重新排列组合,做成自动化的Workflow。
一次制作,反复使用,省时省力,还不用担心中间出错。
比如?
一 、多数据库同时多序列比对(MSA)
多序列比对需要在多个蛋白质数据库里进行查找。
常规使用模式,用户要手动依次在N个数据库里进行搜索,整个过程耗时等于N次搜索的时间之和。
我们可以让不同数据库的搜索同时进行,并做成一个固定Workflow,自动执行,整个过程花费时间将等于耗时最长的数据库搜索时间。既节约时间,又省事。
二 、全计算流程与资源自由组合
不仅仅限于某一个步骤,我们能做全计算流程的自定义Workflow。
上一节我们复习了,AF2第一阶段适合用CPU资源,第二阶段使用GPU计算效果最佳,每个阶段还涉及到不同软件包。
整个计算过程比较复杂,需要在不同阶段的不同步骤使用不同软件包调用不同底层资源进行计算,手动操作工作量不小。而且,常规使用模式,可能会从头到尾使用一种资源计算,这样比较简单,但是会比较吃亏,要么第一阶段GPU纯纯浪费,要么第二阶段慢得吐血,计算时间是原来的数倍。
我们能把整个计算流程与资源自由组合,让用户全程可视化操作,只需要输入不同参数即可。既能实现应用与资源的最佳适配,还能自动化操作,省去大量手动时间。

当然,还有无数种其他组合的可能性。
不止是AlphaFold2,自定义Workflow也能应用在其他场景,戳:1分钟告诉你用MOE模拟200000个分子要花多少钱
03
扫清技术障碍
TB级数据库与I/O瓶颈问题
AF2训练数据库完整版大小约为2.62TB,数据预处理阶段需要在数据库中执行多次随机搜索,这会导致密集的I/O读写。如果数据的读取或写入速度跟不上,就会影响到整个计算过程的效率。
这可能会导致:
1. 同一任务多次计算,耗时却不同;
2. I/O等待超时,任务异常退出;
3. 即便增加CPU资源,也无法加速计算。
为了解决这一问题,我们对整个数据库做了梳理和拆分。其中最大的BFD数据库接近2T,对I/O的要求非常高。
因此,我们将高频I/O的BFD数据库存放在本地磁盘,其他数据库存放在网络共享存储上。
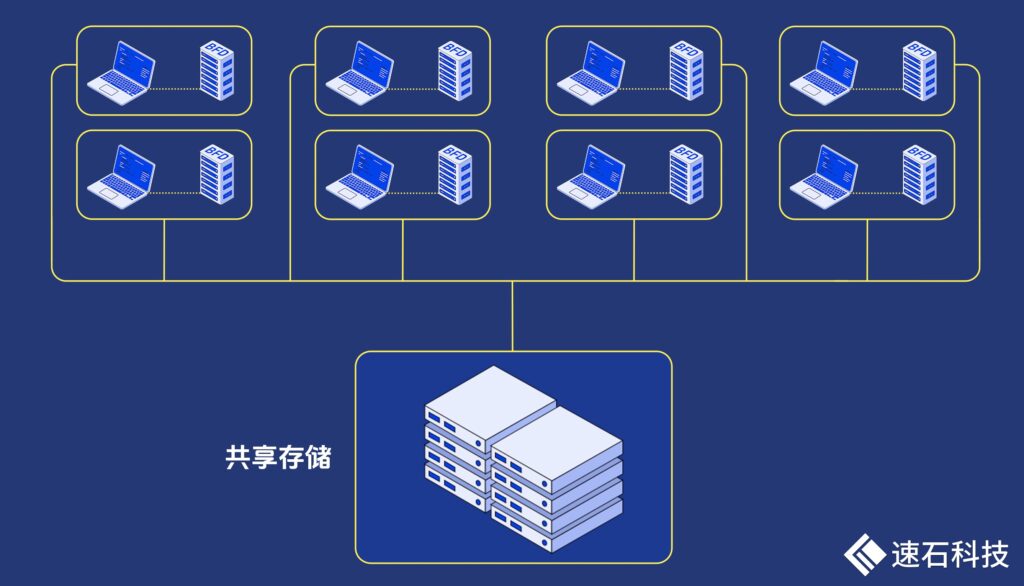
这带来了两大好处:
第一、磁盘空间换时间,计算速度更快
将高频访问的BFD数据库放在本地磁盘上,I/O读写速度快,非常适合需要快速响应的数据。因为本地磁盘是与机器绑定的,如果不止一台机器,这会导致本地磁盘存储空间增加。
而其他对I/O读写速度要求不高的数据库可以放在网络共享存储上,方便所有机器共享读取和写入,减少数据同步问题。
整体来说,用磁盘空间换取时间,让I/O对计算的影响降到最低,显著提升了AF2的运算效率。
第二、为未来可能的大规模并发计算扫清技术障碍
关于这一点,我们进入下一节。
04
大规模并发!
同时预测100+蛋白质结构
对用户来说,不可能一次只预测1个蛋白质结构。
那么,如果要同时预测100+蛋白质结构,怎么玩?
如果是以前,你不但需要搭好运行环境,准备好计算资源,然后一个一个预测,而且每一个还得手动走一遍完整的计算流程。这个过程一听就十分漫长,而且容易出错。
而现在——
已知一:我们有Workflow全流程自动化的能力,单个蛋白质预测已经是一个自动化的Workflow了;
已知二:我们解决了I/O瓶颈问题,也就是说,多台机器对I/O读写瓶颈问题已经解决。
100+蛋白质结构预测,又有什么难的?

现在,我们只需要再多做一步,同时运行有100+个不同输入参数的Workflow,就行了。而完成这一步需要具备两个条件:
一 、充分的CPU/GPU资源
我们调用10万核CPU资源,使用AutoDock Vina帮用户进行了2800万量级的大规模分子对接,将运算效率提高2920倍:提速2920倍!用AutoDock Vina对接2800万个分子
我们智能自动化调度云端GPU/CPU异构资源,包括155个NVIDIA Tesla V100和部分CPU资源,将运算16008个Amber任务的耗时从单GPU的4个月缩短到20小时:155个GPU!多云场景下的Amber自由能计算
二 、调度器能力
这么多机器和任务,怎么适配,按什么策略使用最佳,怎么配置、启动、关闭,提高整体资源利用率,最好还能自动化管理、辅助管理决策等等,甚至怎么DEBUG,这需要的可不止是一点点技术。
详情可戳:国产调度器之光——Fsched到底有多能打?
到这里,这100+蛋白质预测任务,就可以一次性跑完了。
05
V100 VS A100
关于GPU的一点选型建议
那么多GPU型号,你选哪个?
市面上的GPU型号不少,性能和价格差异也很大。
我们选取了3个蛋白质,分别使用V100和A100进行了一轮计算:
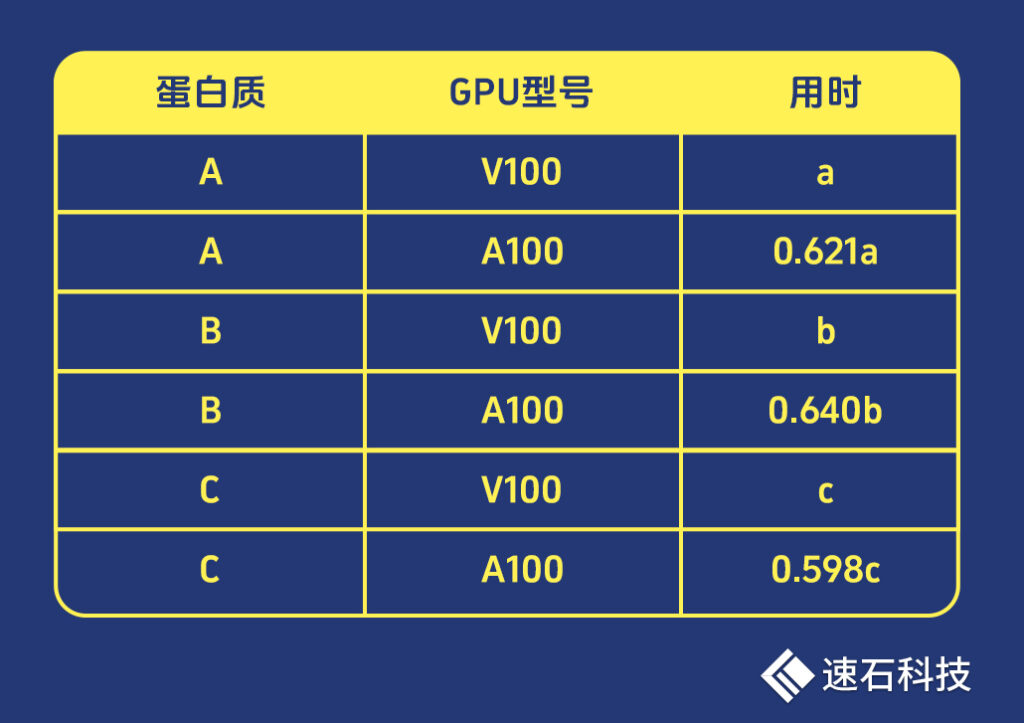
可以看到,对同一个蛋白质进行结构预测,A100用时约为V100的60-64%。
而目前的市场价,无论是小时租赁、包月预留还是裸卡买断,A100至少是V100的2倍以上。
也就是说,A100是以2倍多的价格,去换取约三分之一的性能提升。
两相比较,除非不差钱,我们推荐使用V100。
实证小结
1.AlphaFold2是一个系统,涉及到很多数据库和不同软件,我们的Workflow全流程自动化,让用户可以随心组合,轻松上手蛋白质结构预测;
2.我们用磁盘空间换时间的手段,既解决了TB级数据带来的I/O瓶颈问题,也为大规模并发计算扫清了技术障碍;
3.fastone可支持多个AlphaFold2任务大规模自动并行;
4.GPU也需要选型,我们推荐V100。
本次生信实证系列Vol.15就到这里。
关于fastone云平台在各种BIO应用上的表现,可以点击以下应用名称查看
Vina│Amber│ MOE│ LeDock
速石科技新药研发行业白皮书,可以戳下方查看:
新药研发37问 │顶尖药企AIDD调研
- END -
我们有个一站式新药研发平台
集成行业应用与自编译软件
支持AlphaFold、RoseTTAFold等常用AI应用
可视化Workflow随心创建、便捷分享
提供Zinc、Drugbank等开源/自有分子库
CADD专家团队全面支持扫码
免费试用,送200元体验金,入股不亏~

更多BIO电子书
欢迎扫码关注小F(ID:iamfastone)获取

你也许想了解具体的落地场景:
只做Best in Class的必扬医药说:选择速石,是一条捷径
王者带飞LeDock!开箱即用&一键定位分子库+全流程自动化3.5小时完成20万分子对接
1分钟告诉你用MOE模拟200000个分子要花多少钱
155个GPU!多云场景下的 Amber自由能计算
提速2920倍!用AutoDock Vina对接2800万个分子
新药研发平台:
今日上新——FCP
专有D区震撼上市,高性价比的稀缺大机型谁不爱?
国产调度器之光——Fsched到底有多能打?
创新药研发九死一生,CADD/AIDD是答案吗?
全球44家顶尖药企AI辅助药研行动白皮书
近期重大事件:
速石科技完成龙芯、海光、超云兼容互认证,拓宽信创生态版图
速石科技入驻粤港澳大湾区算力调度平台,参与建设数算用一体化发展新范式
速石科技成NEXT PARK产业合伙人,共同打造全球领先的新兴产业集群
速石科技出席ICCAD2023,新一代芯片研发平台助力半导体企业缩短研发周期
速石科技与芯启源开启战略合作,联手打造软硬件一体芯片研发云平台