语言识别是从多个音频输入样本中识别主要语言的过程。在自然语言处理(NLP)中,语言识别是一个重要的问题,也是一个具有挑战性的问题。有许多与语言相关的任务,例如在手机上输入文本、查找您喜欢的新闻文章或发现您可能遇到的问题的答案。所有这些任务都由NLP模型提供支持。为了决定在特定时间点调用哪个模型,我们必须执行语言识别。
本文介绍了使用英特尔® PyTorch 扩展(针对英特尔处理器进行了优化的 PyTorch AI 框架的一个版本)和英特尔®®神经压缩器(一种在不牺牲准确性的情况下加速人工智能推理的工具)进行语言识别的深入解决方案和代码示例。
该代码示例演示了如何使用拥抱人脸语音大脑* 工具套件训练模型以执行语言识别,并使用英特尔®人工智能分析工具包 (AI Kit) 对其进行优化。用户可以修改代码示例,并使用通用语音数据集识别多达 93 种语言。
语言识别方法
在建议的解决方案中,用户将使用英特尔人工智能分析工具包容器环境来训练模型,并利用英特尔优化的 PyTorch 库执行推理。还有一个选项可以使用英特尔神经压缩器量化训练的模型,以加快推理速度。
数据
对于此代码示例,将使用通用语音数据集,特别是日语和瑞典语的通用语音语料库 11.0。该数据集用于训练强调通道注意力、传播和聚合时间延迟神经网络 (ECAPA-TDNN),该网络使用 Hugging Face SpeechBrain 库实现。延时神经网络 (TDNN),又名一维卷积神经网络 (1D CNN),是多层人工神经网络架构,用于对网络每一层具有移位不变性和模型上下文的模式进行分类。ECAPA-TDNN是一种新的基于TDNN的扬声器嵌入提取器,用于扬声器验证;它建立在原始的 X-Vector 架构之上,更加强调信道注意力、传播和聚合。
实现
下载 Common Voice 数据集后,通过将 MP3 文件转换为 WAV 格式来对数据进行预处理,以避免信息丢失,并分为训练集、验证集和测试集。
使用Hugging Face SpeechBrain库使用Common Voice数据集重新训练预训练的VoxLingua107模型,以专注于感兴趣的语言。VoxLingua107 是一个语音数据集,用于训练口语识别模型,这些模型可以很好地处理真实世界和不同的语音数据。此数据集包含 107 种语言的数据。默认情况下,使用日语和瑞典语,并且可以包含更多语言。然后,此模型用于对测试数据集或用户指定的数据集进行推理。此外,还有一个选项可以利用SpeechBrain的语音活动检测(VAD),在随机选择样本作为模型的输入之前,仅从音频文件中提取和组合语音片段。此链接提供了执行 VAD 所需的所有工具。为了提高性能,用户可以使用英特尔神经压缩器将训练好的模型量化为整数 8 (INT8),以减少延迟。
训练
训练脚本的副本将添加到当前工作目录中,包括 - 用于创建 WebDataset 分片,- 执行实际训练过程,以及 - 配置训练选项。用于创建 Web数据集分片和 YAML 文件的脚本经过修补,可与此代码示例选择的两种语言配合使用。create_wds_shards.pytrain.pytrain_ecapa.yaml
在数据预处理阶段,执行脚本随机选择指定数量的样本,将输入从MP3转换为WAV格式。在这里,这些样本中有 80% 将用于训练,10% 用于验证,10% 用于测试。建议至少 2000 个样本作为输入样本数,并且是默认值。prepareAllCommonVoice.py
在下一步中,将从训练和验证数据集创建 WebDataset 分片。这会将音频文件存储为 tar 文件,允许为大规模深度学习编写纯顺序 I/O 管道,以便从本地存储实现高 I/O 速率——与随机访问相比,大约快 3-10 倍。
用户将修改 YAML 文件。这包括设置 WebDataset 分片的最大数量值、将神经元输出为感兴趣的语言数量、要在整个数据集上训练的纪元数以及批大小。如果在运行训练脚本时 CPU 或 GPU 内存不足,则应减小批大小。
在此代码示例中,将使用 CPU 执行训练脚本。运行脚本时,“cpu”将作为输入参数传递。中定义的配置也作为参数传递。train_ecapa.yaml
运行脚本以训练模型的命令是:
python train.py train_ecapa.yaml --device "cpu"
将来,培训脚本 train.py 将设计为适用于英特尔® GPU,如英特尔®数据中心 GPU Flex 系列、英特尔数据中心 GPU Max 系列和英特尔 Arc™ A 系列,并更新了英特尔®®扩展 PyTorch。
运行训练脚本以了解如何训练模型和执行训练脚本。建议将此迁移学习应用使用第四代英特尔至强®可扩展处理器,因为它通过其英特尔高级矩阵扩展(英特尔®®® AMX)指令集提高了性能。
训练后,检查点文件可用。这些文件用于加载模型以进行推理。
推理
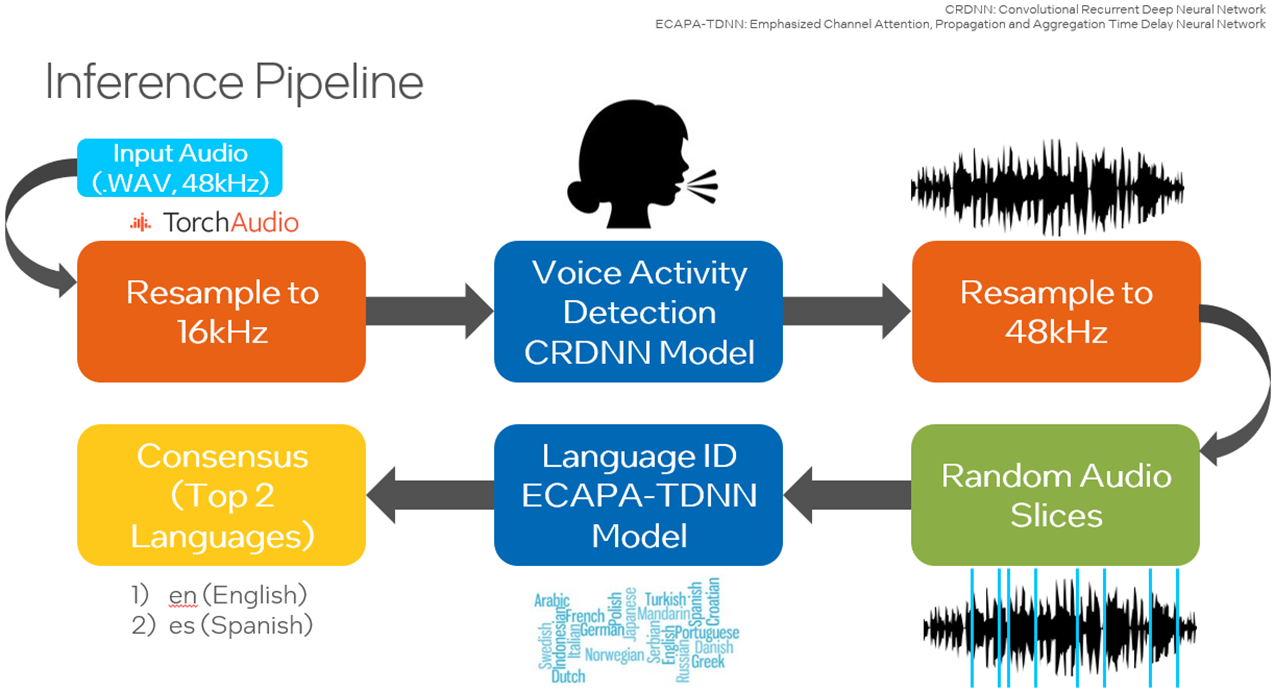
运行推理之前的关键步骤是修补 SpeechBrain 库的预训练文件,以便可以运行 PyTorch TorchScript* 以改善运行时。TorchScript 要求模型的输出只是张量。interfaces.py
用户可以选择使用 Common Voice 中的测试集或他们自己的 WAV 格式自定义数据运行推理。以下是推理脚本 () 可用于运行的选项:inference_custom.py and inference_commonVoice.py
| 输入选项 | 描述 |
| -p | 指定数据路径。 |
| -d | 指定波采样的持续时间。默认值为 3。 |
| -s | 指定采样波的大小,默认值为 100。 |
| --瓦德 | (仅限“inference_custom.py”)启用 VAD 模型以检测活动语音。VAD 选项将识别音频文件中的语音片段,并构造一个仅包含语音片段的新.wav文件。这提高了用作语言识别模型输入的语音数据的质量。 |
| --易派克 | 使用英特尔扩展 PyTorch 优化运行推理。此选项会将优化应用于预训练模型。使用此选项应可提高与延迟相关的性能。 |
| --ground_truth_compare | (仅限“inference_custom.py”)启用预测标签与地面真实值的比较。 |
| --详细 | 打印其他调试信息,例如延迟。 |
必须指定数据的路径。默认情况下,将从原始音频文件中随机选择 100 个 3 秒的音频样本,并用作语言识别模型的输入。
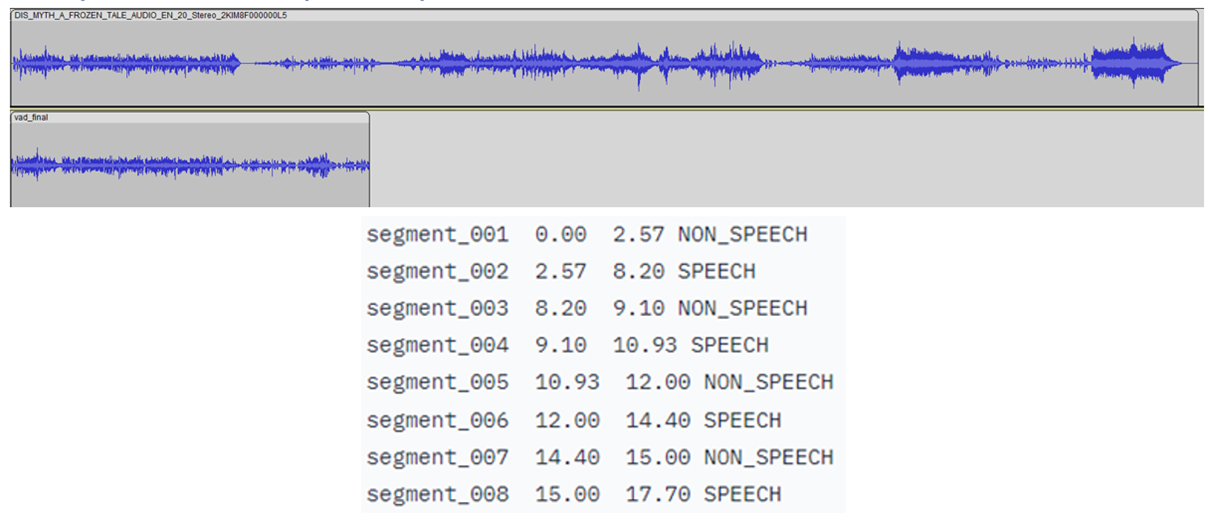
在LibriParty数据集上预训练的小型卷积递归深度神经网络(CRDNN)用于处理音频样本并输出检测到语音活动的片段。这可以通过选项在推理中使用。--vad
如下图所示,将检测到语音的时间戳是从 CRDNN 模型传送的,这些时间戳用于构建仅包含语音的较短的新音频文件。从这个新的音频文件中采样将更好地预测所说的主要语言。
自行运行推理脚本。运行推理的示例命令:
python inference_custom.py -p data_custom -d 3 -s 50 --vad
这将对您提供的位于data_custom文件夹中的数据运行推理。此命令使用语音活动检测对 50 个随机选择的 3 秒音频样本执行推理。
如果要运行其他语言的代码示例,请下载其他语言的通用语音语料库 11.0 数据集。
针对 PYTORCH 和英特尔神经压缩器的英特尔扩展优化
PyTorch
英特尔扩展扩展了 PyTorch 的最新功能和优化,从而进一步提升了英特尔硬件的性能。查看如何安装 PyTorch 的英特尔扩展。扩展可以作为 Python 模块加载,也可以作为C++库链接。Python 用户可以通过导入 .intel_extension_for_pytorch
- CPU 教程提供了有关适用于英特尔 CPU 的 PyTorch 英特尔扩展的详细信息。源代码可在主分支处获得。
- GPU 教程提供了有关适用于英特尔 GPU 的 PyTorch 英特尔扩展的详细信息。源代码可在 xpu-master 分支获得。
要使用英特尔 PyTorch 扩展优化模型以进行推理,可以传入该选项。使用插件优化模型。TorchScript 加快了推理速度,因为 PyTorch 以图形模式运行。使用此优化运行的命令是:--ipex
python inference_custom.py -p data_custom -d 3 -s 50 --vad --ipex --verbose
注意:需要该选项才能查看延迟测量值。--verbose
自动混合精度(如 bfloat16 (BF16) 支持)将在代码示例的未来版本中添加。
英特尔神经压缩器
这是一个在 CPU 或 GPU 上运行的开源 Python 库,它:
- 执行模型量化,以减小模型大小并提高深度学习推理的部署速度。
- 跨多个深度学习框架自动执行常用方法,例如量化、压缩、修剪和知识蒸馏。
- 是 AI 套件的一部分
通过在传入模型和验证数据集的路径的同时运行脚本,可以将模型从 float32 (FP32) 精度量化为整数 8 (INT8)。以下代码可用于加载此 INT8 模型以进行推理:quantize_model.py
from neural_compressor.utils.pytorch import load
model_int8 = load("./lang_id_commonvoice_model_INT8", self.language_id)
signal = self.language_id.load_audio(data_path)
prediction = self.model_int8(signal)
请注意,加载量化模型时需要原始模型。使用 FP32 量化训练模型到 INT8 的命令是:quantize_model.py
python quantize_model.py -p ./lang_id_commonvoice_model -datapath $COMMON_VOICE_PATH/commonVoiceData/commonVoice/dev
以上是关于使用 PyTorch 构建端到端 AI 解决方案的一些介绍。
- END -
我们有个AI研发云平台
集成多种AI应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送200元体验金,入股不亏~

更多电子书欢迎扫码关注小F(ID:iamfastone)获取
你也许想了解具体的落地场景:
王者带飞LeDock!开箱即用&一键定位分子库+全流程自动化,3.5小时完成20万分子对接
这样跑COMSOL,是不是就可以发Nature了
Auto-Scale这支仙女棒如何大幅提升Virtuoso仿真效率?
1分钟告诉你用MOE模拟200000个分子要花多少钱
LS-DYNA求解效率深度测评 │ 六种规模,本地VS云端5种不同硬件配置
揭秘20000个VCS任务背后的“搬桌子”系列故事
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
关于为应用定义的云平台:
当仿真外包成为过气网红后…
和28家业界大佬排排坐是一种怎样的体验?
这一届科研计算人赶DDL红宝书:学生篇
杨洋组织的“太空营救”中, 那2小时到底发生了什么?
一次搞懂速石科技三大产品:FCC、FCC-E、FCP
Ansys最新CAE调研报告找到阻碍仿真效率提升的“元凶”
国内超算发展近40年,终于遇到了一个像样的对手
帮助CXO解惑上云成本的迷思,看这篇就够了
花费4小时5500美元,速石科技跻身全球超算TOP500