
新思科技(Synopsys)家的VCS,在半导体行业使用率极高,背景我们就不多说了。
对经常跑EDA或其他算力密集型任务的用户来说,在深度掌握本行业业务知识及熟练运用常见EDA工具以外,通常还需要在技能树上点上一门技能——IT,就是怎么(顺利)使用机器把手里的任务给(高效)跑完。
他们的IT技能升级打怪之旅一般分为三个阶段:
第一阶段:单机单CPU核,单任务
第二阶段:单机多CPU核,多任务
第三阶段:多机多CPU核,多任务
据我们观察,很多用户都已经处在第二阶段。
但是,依然有部分用户尚处在第一阶段,比如我们今天的实证主角。
我们之前的六篇实证都直接一步到位——上云后。
HSPICE │ Bladed │Vina │OPC │Fluent │Amber
今天我们看看上云前的幕后系列,又名:搬桌子的故事。
用户需求
某IC设计公司运行EDA仿真前端设计和后端设计的分析任务,进行机电一体芯片技术的开发。现有机房设备较为老旧,共有8台单机,需要同时服务数字和模拟两个研发部门。
随着公司业务的发展,相关部门负责人几乎同时反馈业务峰值时计算资源严重不足,排队现象严重。
实证目标
1、fastone平台是否能有效提升VCS任务运行效率?
2、fastone平台是否能有效提升本地机器资源利用率?
3、fastone平台是否支持大规模VCS任务自动化稳定运行?
实证参数
平台:fastone企业版产品
应用:Synopsys VCS
适用场景:数模混合电路仿真
系统:Red Hat Enterprise release 5.7(Tikanga)
实证结果
我们先来看看用户自己跑20000个任务和我们来跑的效果:
大规模任务验证 20000个任务
我们将本地机房的8台单机构建为一个统一管理的集群,运行20000个VCS任务的时间是用户自己所需时间的约1/50。
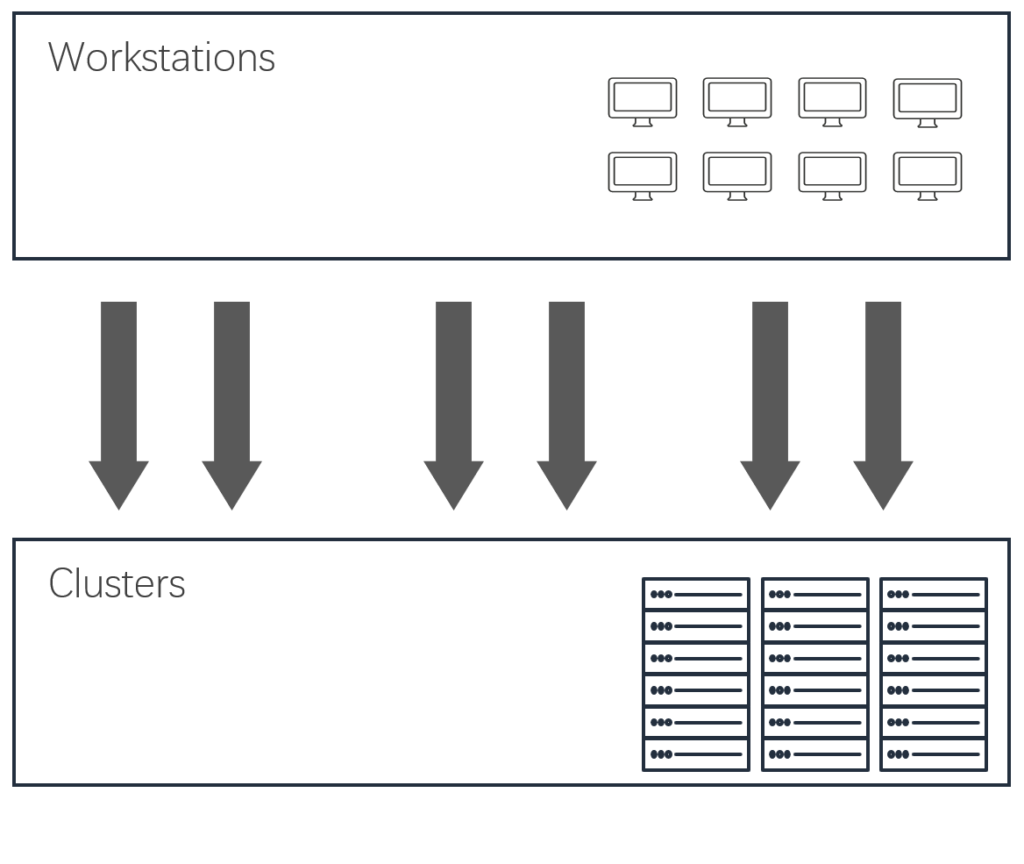
实证过程:
1、用户使用一台单机C1运行20000个VCS任务,耗时40485分钟;
2、将本地机房的所有8台单机构建为集群A,使用集群A运行20000个VCS任务,耗时809分钟。

用户按常理推断,本地机房共有8台单机,将所有机器一起来运行大规模VCS任务的时间大概应该是使用一台机器机耗时的6-7倍(理想值为8倍,但由于存在长尾任务,存在一定差异)。
但实证中50倍的提升大大超出了他们的预期。
中间发生了什么?
回到我们开头说的三个阶段——
第一阶段:单机单CPU核,单任务
单任务状态下的单机单核,就是一个任务只在一台机器上的一个CPU上跑。不管这台机器其实有几个CPU,反正就只用一个。资源利用率极其低下,可以说是暴殄天物。
再细一点,这里其实还有个1.5阶段:单机多CPU核,单任务。效果类似。
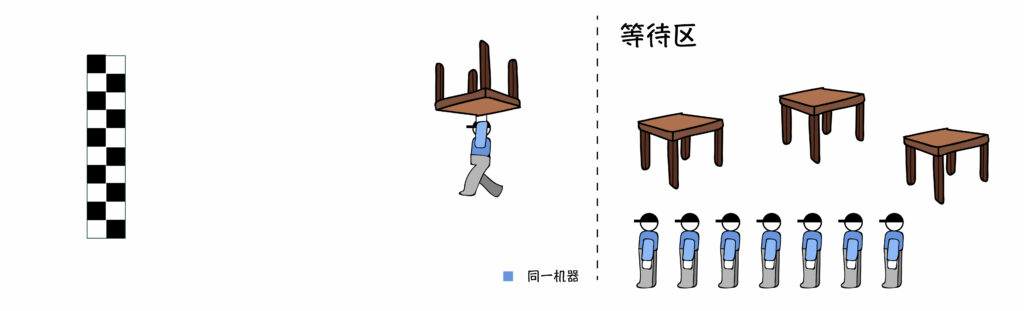
假设给你几个人(CPU核),完成一个叫做“搬桌子”的任务。
单任务的处理方式分为单进程和多进程:
单进程的处理方式是:不管你有几个人,同一时间永远只有1个人在搬整张桌子,其他人在围观。
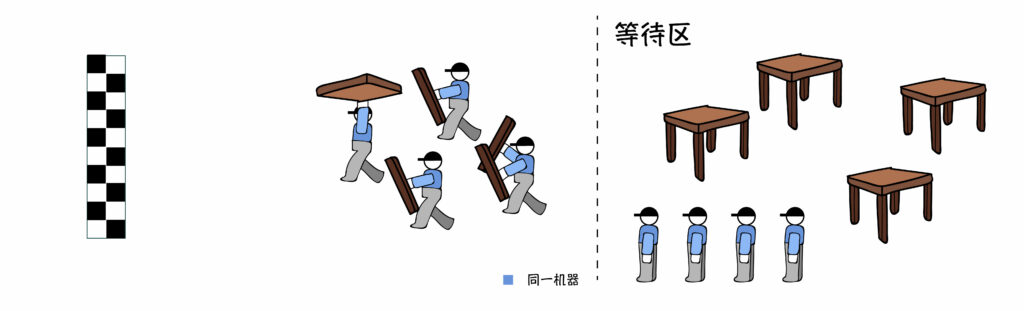
多进程的处理方式是:
先拆桌子。比如把一张桌子拆成4个零部件,分给4个人来同时搬,有的搬桌子腿,有的搬桌面等等,搬得最慢的人决定任务的完成速度。
但是,哪怕你有8个人,一次也只有4个人在搬。
搬完一张桌子再搬下一张,依次往复。
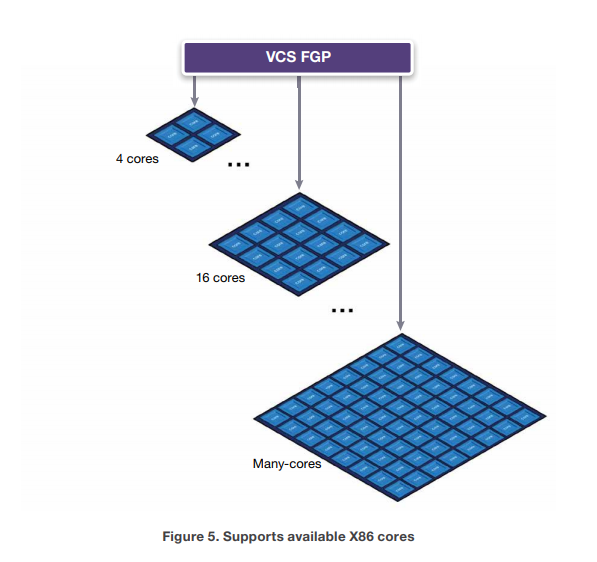
补充一个背景信息:2009年4月,新思科技就发布了VCS的多核技术,通过将耗时的计算处理动态地分配至多个CPU内核来突破芯片验证的瓶颈,从而提高验证的速度。
也就是说,应用十多年前就支持单任务多进程了,现在这个技术的名字叫Fine-Grained Parallelism,FGP。
第二阶段:单机多CPU核,多任务
多任务状态下的单机多核,就是多个任务能同时在一台机器上的数个CPU上跑,受制于单台机器的最大核数,目前最多也就96个核了。
我们继续讲“搬桌子”。
上一阶段的多进程处理方式,存在一个明显的问题。哪怕你有8个人,一次也只有4个人在搬。搬完一张桌子再搬下一张。
这就很不合理了。
于是我们在此基础上改进了一下。
在你有8个人的情况下,一张桌子4个人搬,我们可以同时搬两张桌子啦。这样可以明显加快任务的完成速度。
但是,单台机器的总CPU核数就是上限了。
当然这一阶段还是会存在一些问题,会出现有人突然跳出来跟你抢人或者你也搞不清楚哪些人现在有空来帮你。
因为资源使用的不透明和缺乏有序管理,会出现不同人对同一资源的争抢,任务排队等现象。同时,你会发现资源利用率还是不高。
不少用户已经处在这一阶段。
我们看看从第一阶段到第二阶段的实际VCS验证效果:
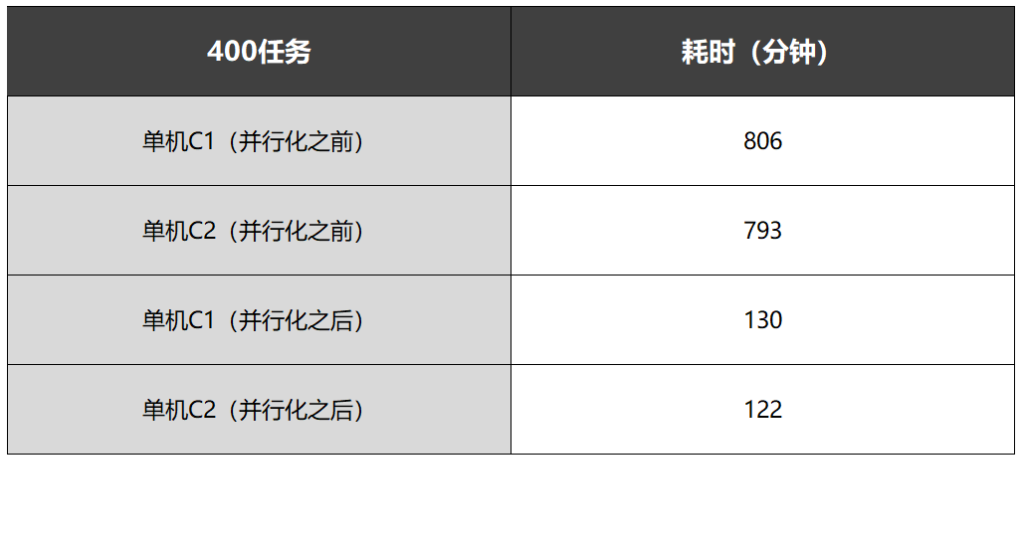
应用并行化验证 400个任务
对VCS进行多任务并行化处理后,一台单机运行相同VCS任务的时间缩短为原先的15%-16%,极大提升了运行效率。
实证过程:
1、使用一台单机C1(8核)运行400个VCS任务,耗时806分钟;
2、使用一台单机C2(8核)运行400个VCS任务,耗时793分钟;
3、对VCS应用进行多任务并行化处理后,使用一台单机C1(8核)运行400个VCS任务,耗时130分钟;
4、对VCS应用进行多任务并行化处理后,使用一台单机C2(8核)运行400个VCS任务,耗时122分钟。
第三阶段:多机多CPU核,多任务
多任务状态下的多机多核,就是多个任务能同时在数台机器的数个CPU上跑,这个我们称之为集群化管理,一般都需要有调度器的参与。
关于调度器的相关知识,看这里:亿万打工人的梦:16万个CPU随你用
前面讲到我们已经可以同时安排搬两张桌子啦。但其实,如果你的机器足够多,人(CPU核)足够多,你完全可以同时搬更多的桌子。
这个时候,必然要面临一个如何调兵遣将的问题。
这么多机器,这么多任务,怎么顺利一一配置、启动、关闭,提高整体资源利用率,最好还能自动化管理等等。这就需要一点技术了。
至于云上资源的大规模动态化调度和管理,要更加高阶一点。
在《生信云实证Vol.3:提速2920倍!用AutoDockVina对接2800万个分子》中,我们最多调用了10万核CPU资源对整个VS数据库进行虚拟筛选。
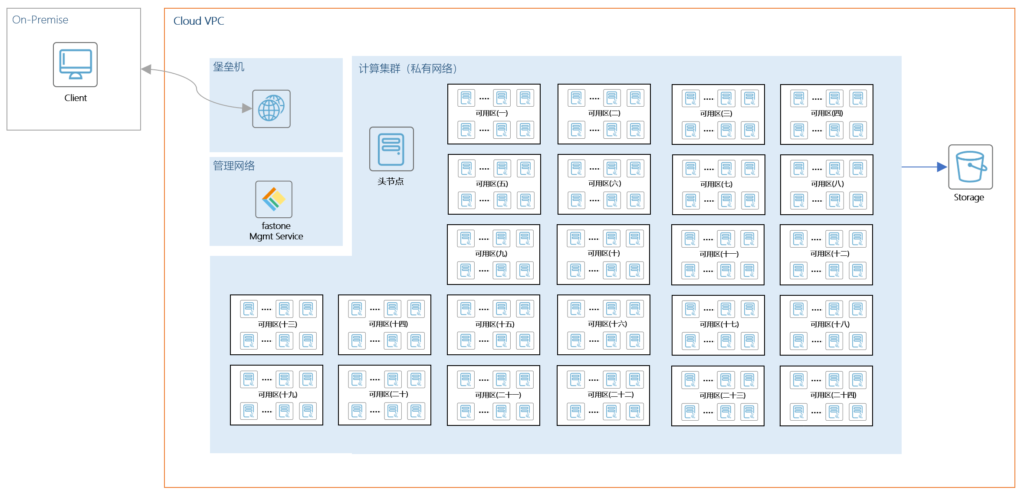
当集群达到如此规模之后,手动管理是不可想象的。
而且云上资源跟本地不同,往往是个动态使用的过程,有时候甚至要抢。
更不用说还要考虑不同用户在不同阶段的策略和需求。
我们看看从第二阶段到第三阶段的实际VCS验证效果:
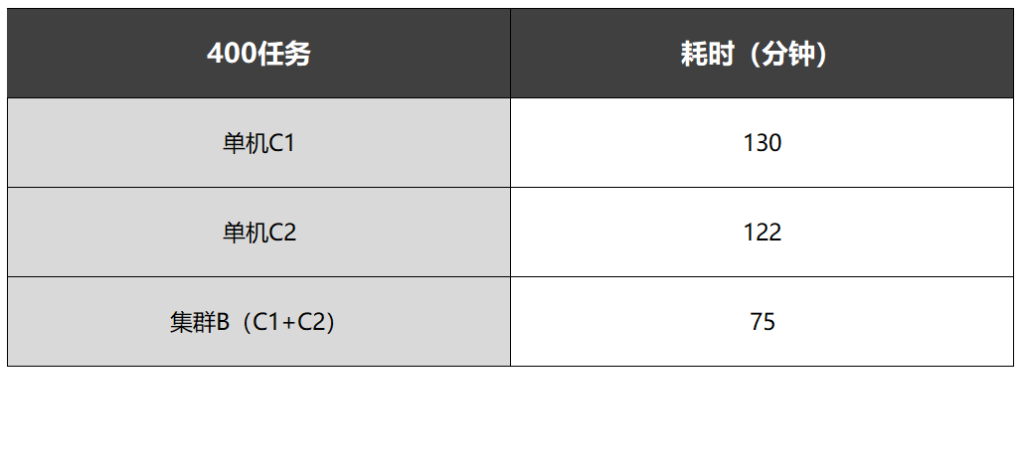
集群化验证 400个任务
由2台单机构建的集群运行相同VCS任务的时间为单机的约60%,并实现了自动化资源管理。
实证过程:
1、使用一台单机C1(8核)运行400个VCS任务,耗时130分钟;
2、使用一台单机C2(8核)运行400个VCS任务,耗时122分钟;
3、将C1和C2构建为集群B,使用集群B运行400个VCS任务,耗时75分钟。
最后,我们回顾一下,我们到底做了哪些事:
应用并行化:从单任务到多任务
fastone帮助用户实现了应用并行化,可以充分使用一台单机上的全部CPU资源,确保了最大的计算效率。
资源集群化:从单机到集群
fastone帮助用户实现了集群化管理,让多台机器能够并行化运行VCS任务,实现了数据、应用、资源的统一化管理。
规模自动化:从400个任务到20000个任务
用户希望在面临大规模VCS任务时,上述方案的稳定性能够得到充分验证。
fastone帮助用户充分验证了20000个VCS任务场景下,能够自动化规模化地调度资源高效完成任务,满足用户需求。
到现在为止,我们成功帮助用户从单机单任务单进程运行的阶段大幅度跨越到了大规模任务自动化集群化运行阶段。
万事俱备,下一步,上云。
我们的前两篇EDA云实证可以了解一下:
《从30天到17小时,如何让HSPICE仿真效率提升42倍?》
《 5000核大规模OPC上云,效率提升53倍》
本次EDA行业云实证系列Vol.7就到这里了。
下一期的EDA云实证,我们聊Virtuoso。
请保持关注哦!
- END -
我们有个为应用定义的云平台
集成多种应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送200元体验金,入股不亏~

更多电子书欢
迎扫码关注小F(ID:imfastone)获取

你也许想了解具体的落地场景:
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
你可能感兴趣:
2小时,账单47万!「Milkie Way公司破产未遂事件」复盘分析
【2021】全球44家顶尖药企AI辅助药物研发行动白皮书
EDA云平台49问
国内超算发展近40年,终于遇到了一个像样的对手
帮助CXO解惑上云成本的迷思,看这篇就够了
灵魂画师,在线科普多云平台/CMP云管平台/中间件/虚拟化/容器是个啥
花费4小时5500美元,速石科技跻身全球超算TOP500







