LS-DYNA是一个以显式求解为主,隐式求解为辅的通用非线性动力有限元分析程序,核心是求解器。
用户主要是高校/科研机构和航空航天、汽车、电子/高科技、船舶、土木工程、制造和生物工程等行业,包括汽车碰撞、爆炸反应,甚至主动脉人工心脏瓣膜在血液泵送通过时的复杂启闭行为。
1976年,LS-DYNA由美国Lawrence Livermore国家实验室的J.O.Hallquist博士主持开发。
1988年,LSTC(Livermore Software Technology Corp.)公司成立,LS-DYNA开始商业化。
1996年,LSTC与ANSYS合作推出ANSYS/LS-DYNA,结合了ANSYS的前、后处理工具和LS-DYNA求解器。
2019年,Ansys收购LSTC。
- 如何提高求解器的计算效率?
- 本地和云上仿真并行计算是一回事吗?
- 什么类型的云端资源更适合跑LS-DYNA?
- LS-DYNA大规模并行计算效率优化明显吗?
- 在云上运行会改变用户本地的使用习惯吗?
今天我们通过一个实证来解答用户在使用LS-DYNA上云过程中的这些关键问题。
用户需求
某车企CAE部门建设有本地机房,日常工作使用单机计算,不仅算得慢,且由于资源未得到统一管理,经常出现高性能机器排队、低配机器空闲的情况,严重拖慢生产设计进度。
随着公司业务的发展,CAE部门将在不久的将来面临更大的业务压力,部门负责人有意将部分LS-DYNA任务扩展到云端,但由于没有接触过云,有很多疑问。
实证目标
1、LS-DYNA任务能否在云端有效运行?计算效率能否优化?
2、LS-DYNA应用最适合的云端资源是哪种类型?
3、LS-DYNA大规模并行场景是否依然能保持线性?
4、fastone能否进行资源统一管理,同时保持用户本地的使用习惯?
实证参数
平台:
fastone企业版产品
应用:
LS-DYNA MPP版本
操作系统:
Linux CentOS 7.4
调度器:
SLURM
适用场景:
仿真材料在承受短时高强度载荷时的响应,如碰撞、跌落以及金属成型过程中发生的情况
云端硬件配置:
计算优化型实例
通用型实例
内存优化型实例
网络加强型实例
技术架构图:
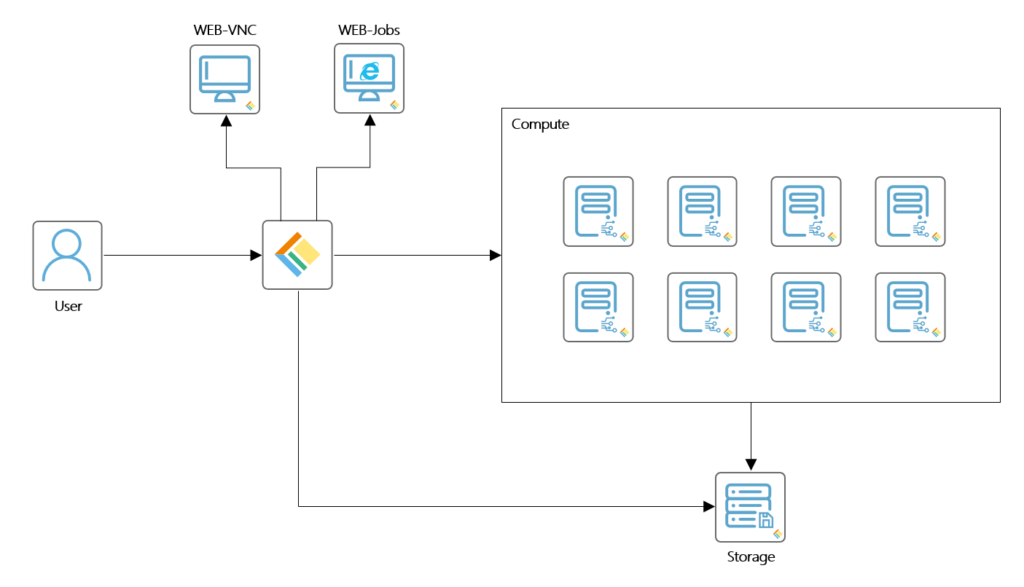
LS-DYNA支持基于Linux、Windows和UNIX的大规模集群的并行仿真计算,分为MPP(Massively Parallel Processing)版本和SMP(Symmetric Multi-Processing)版本。
SMP版本是多个CPU之间共享相同的内存总线等资源,一般只能在单机上运行,受单机CPU性能及CPU核数限制。MPP版本是每个CPU有独享的内存总线等资源,CPU之间通过网络通信交换信息,可以在计算机集群上进行计算,大幅提升计算速度。
单机和多机计算背后的详细原理和意义在《EDA云实证Vol.7:揭秘20000个VCS任务背后的“搬桌子”系列故事》里解释得非常清楚。
虽然应用不同,原理是一样的。
和Fluent一样,随着计算节点规模地增加,LS-DYNA有很明显的节点之间数据交换造成的通信开销,造成信息延时。可以回顾一下《CAE云实证Vol.5:怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?》
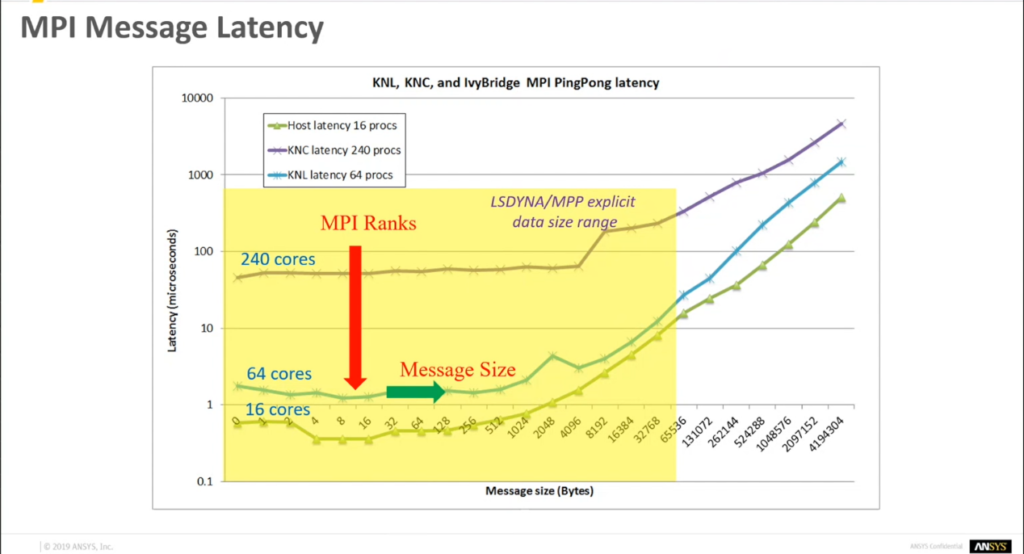
下图这张PingPong测试(顾名思义就是找一个数据包不断地在两个节点之间丢来丢去,像打乒乓球一样。)能看出从16 cores到240 cores,随着核数增加,信息延时显著高出一个数量级。而随着通信数据增加到一定程度,信息延时会出现爆发性增长。
为了充分解答用户的疑惑,我们选择了不同类型,不同代际与不同规模的云资源,分别做了以下场景的验证。
实证场景一:不同类型配置
本地 VS 云端计算优化型实例 VS 云端通用型实例 VS 云端内存优化型实例
结论:
1、同等核数下,云端计算优化型实例的表现优于通用型实例、内存优化型实例和本地计算资源;
2、随着核数的上升,由于节点间通信开销指数级上升,性能的提升随着线程数增长逐渐变缓。当核数增加到128核后,云端计算优化型实例与本地资源运行相同LS-DYNA所需的时间相差无几。
实证过程:
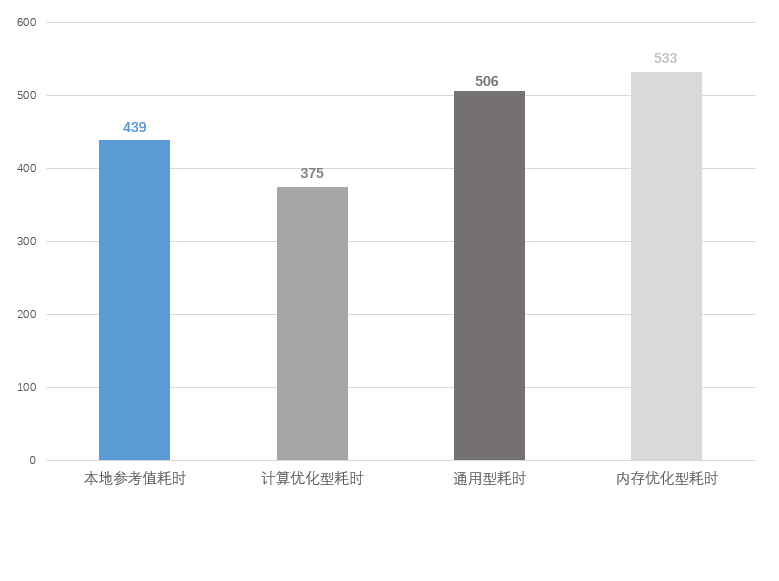
1、本地使用64核计算资源运算一组LS-DYNA任务,耗时439分钟;
2、云端调度64核计算优化型实例运算一组LS-DYNA任务,耗时375分钟;
3、云端调度64核通用型实例运算一组LS-DYNA任务,耗时506分钟;
4、云端调度64核内存优化型实例运算一组LS-DYNA任务,耗时533分钟;
5、本地分别使用16、32、48、64、96、128核计算资源运算同一组LS-DYNA任务,耗时分别为1404、821、566、439、321、255分钟;
6、云端分别调度16、32、48、64、96、128核计算优化型实例运算同一组LS-DYNA任务,耗时分别为1269、662、458、375、299、252分钟。
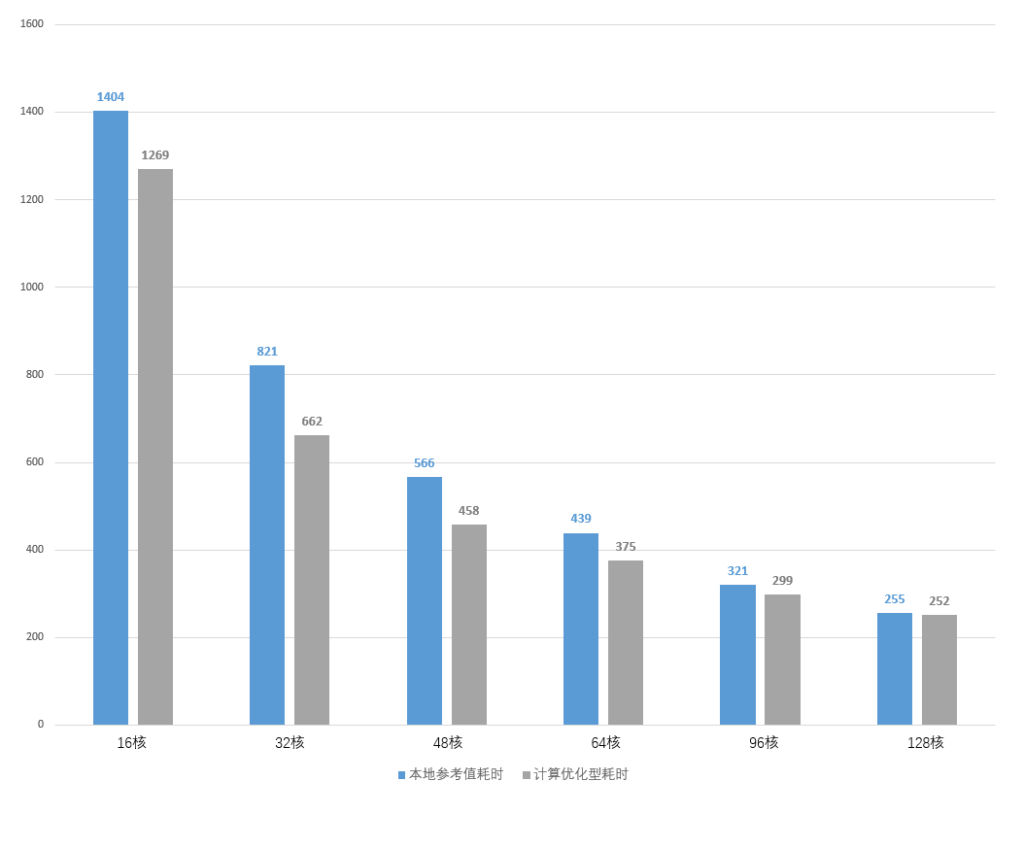
可以看到当核数较少时,计算优化型实例的耗时要明显少于本地资源,但随着核数的增加,两者的耗时逐渐接近,尤其是在128核时,计算优化型实例几乎已经丧失了所有的优势。
实证场景二:不同代际,同样类型配置
本地 VS 云端计算优化型实例 VS 新一代云端计算优化型实例
结论:
新款计算优化型实例运算效率相比旧款提升约15%,且价格更便宜,但同样存在线性不足的问题。
实证过程:
1、本地分别使用16、32、48、64、96、128核计算资源运算同一组LS-DYNA任务,耗时分别为1404、821、566、439、321、255分钟;
2、云端分别调度16、32、48、64、96、128核计算优化型实例运算同一组LS-DYNA任务,耗时分别为1269、662、458、375、299、252分钟;
3、云端分别调度16、32、48、64、96、128核新款计算优化型实例运算同一组LS-DYNA任务,耗时分别为1088、569、391、320、255、216分钟。
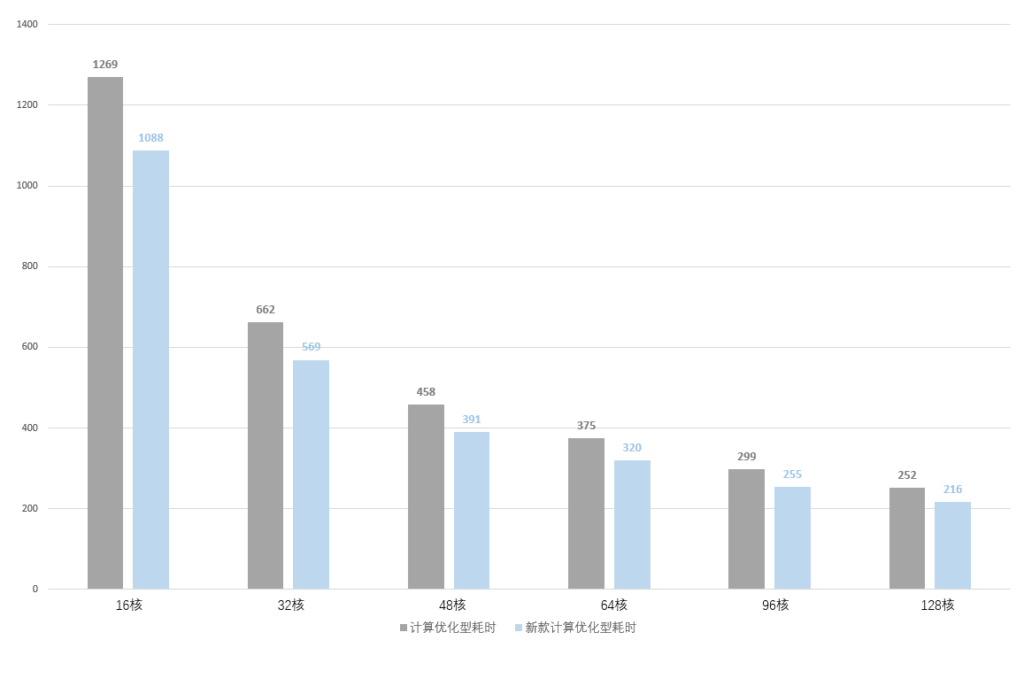
新款计算优化型实例无论是在低核数还是高核数下相比老款均有约15%的性能提升。
那么价格又如何呢?
我们来感受一下不同云厂商多款计算优化型实例的价格差异:
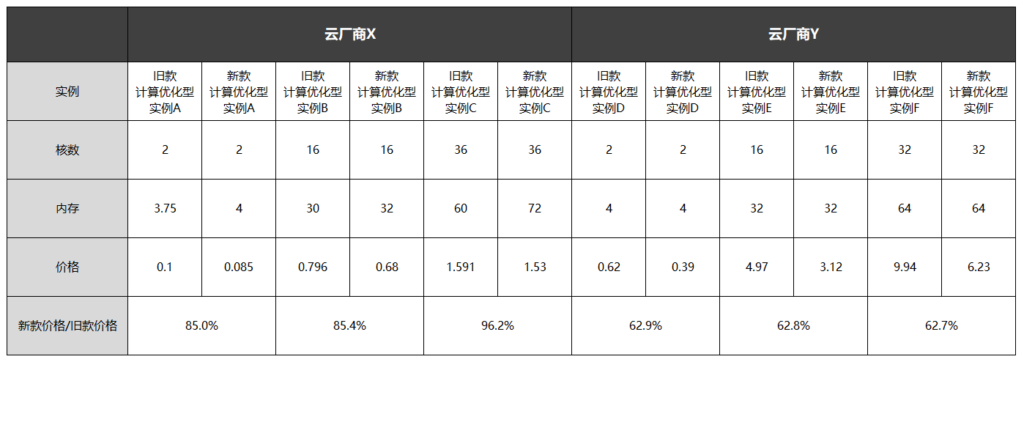
在同等规格下,新款的价格普遍要比旧款便宜,最低甚至接近六折。
当然,并不是所有的云端新款实例都比旧款又快又便宜。
比如我们之前在运算Amber任务时,NVIDIA Tesla K80(2014年上市)的耗时是V100(2017年上市)的约5-6倍,价格却只有后者的三分之一。
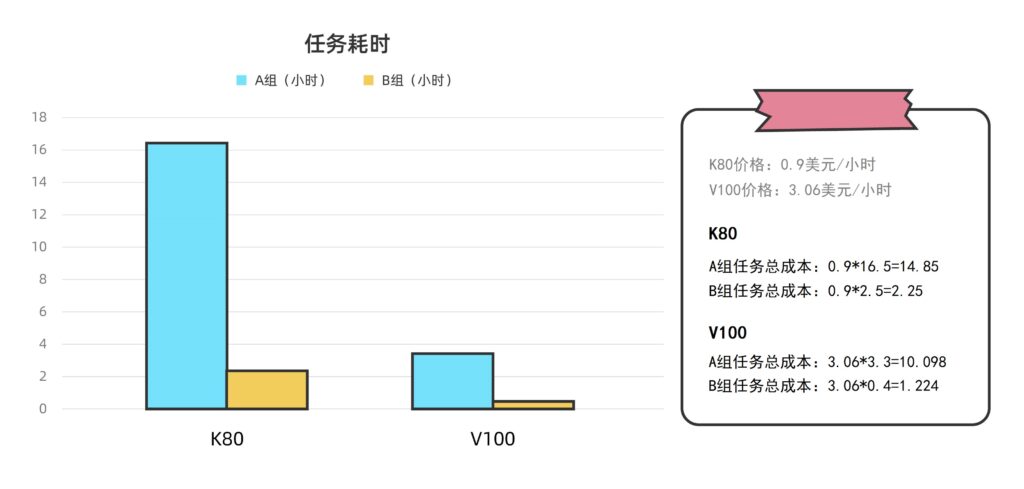
这种时候,我们必须在时间和金钱之间做出一些取舍。详细可以看这里《生信云实证Vol.6:155个GPU!多云场景下的Amber自由能计算》
我们有一份六大公有云厂商云服务器资源价格全方位对比报告,帮助你对主流厂商的资源价格了如指掌:《六家云厂商价格比较:AWS/阿里云/Azure/Google Cloud/华为云/腾讯云》
同为计算优化型实例,不管新款旧款,都没有解决LS-DYNA任务大规模并行计算不线性问题。
这个问题的解决方案在哪里?
我们看下一个场景:
实证场景三:不同规模云端扩展性验证
本地 VS 云端计算优化型实例 VS 云端网络加强型实例
结论:
1、在云端使用网络加强型实例,调度128核计算资源,最多可将运算一组LS-DYNA任务的耗时缩短到135分钟,只有本地资源和云端计算优化型实例耗时的约二分之一;
2、网络加强型实例有效解决了LS-DYNA任务并行计算节点间通信问题,在云上展现了良好的线性扩展性。
实证过程:
1、本地分别使用16、32、48、64、96、128核计算资源运算同一组LS-DYNA任务,耗时分别为1404、821、566、439、321、255分钟;
2、云端分别调度16、32、48、64、96、128核计算优化型实例运算同一组LS-DYNA任务,耗时分别为1269、662、458、375、299、252分钟;
3、云端分别调度16、32、48、64、96、128核新款计算优化型实例运算同一组LS-DYNA任务,耗时分别为1088、569、391、320、255、216分钟;
4、云端分别调度16、32、48、64、96、128核网络加强型实例运算同一组LS-DYNA任务,耗时分别为1202、603、404、307、209、163分钟。
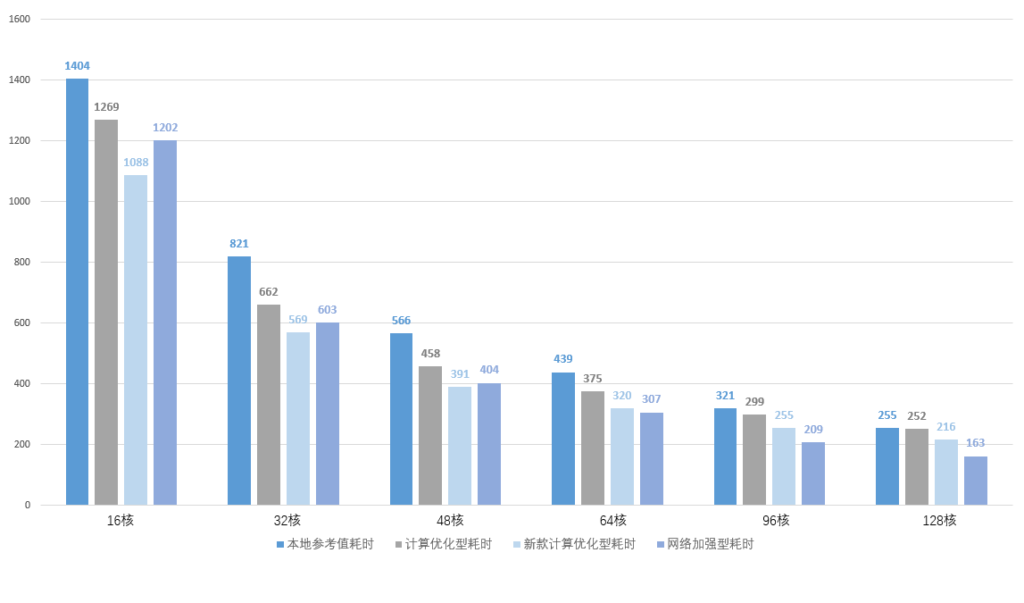
从上表中可以明显地观察到,网络加强型实例虽然在低核数下的表现并不起眼,但随着核数的增加,性能提升幅度相当大,在128核的环境下相比本地资源的性能提升将近一倍,线性表现堪称完美。
在之前的Fluent实证中,我们也验证了这一点。
用户的原有使用习惯需不需要改变呢?
在Fluent实证里,我们的切入角度是任务提交方法:
通过journal标准流程化 VS Fluent应用图形界面两种模式,适配不同基础的用户类型。
这次我们换一个角度——数据传输方法和习惯。
用户在本地:
不论是单机模式还是使用服务器集群,用户只需要把数据传到本地机器或服务器上,便可以直接跑任务,当然后面可能有IT部门会完成服务器端数据管理工作。
用户自己使用云:
用户将数据传到本地机器或服务器之后,还需要在云端开启资源、搭建环境,手动进行数据的上传和下载。
用户使用我们平台:
和本地一样,用户只需要把数据上传到我们的DM(Data Manager)工具上,就可以直接使用数据来跑任务了。
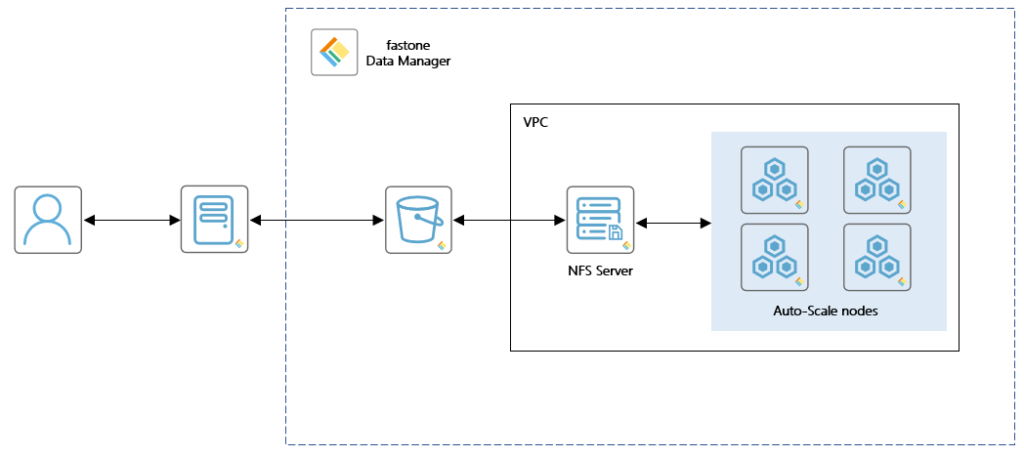
手动模式和自动模式的巨大差异,可以见这篇《EDA云实证Vol.1:从30天到17小时,如何让HSPICE仿真效率提升42倍?》

对于用户而言,使用我们的DM工具至少有三大优势:
1、自动关联集群,不改变操作习惯
用户无需在多套认证系统之间切换,使用统一的身份认证即可传输数据,并自动关联云端集群进行计算,不改变其原有的使用习惯。
2、一次上传,多次使用
数据只需上传一次即可多次使用,其他用户在经过统一认证后也可随时共享,极大提升团队协同能力。
3、大幅提升传输效率
关于这点,我们在这篇《CAE云实证Vol.2:从4天到1.75小时,如何让Bladed仿真效率提升55倍?》里有提到,用户在跑Bladed任务之前需要上传多达数百GiB的风文件。
而且,随着任务的调整,有大量小文件需要增量上传。在这个实证中,用户需要上传9600个任务文件,每个几十MiB不等。
我们的DM工具能很好地满足用户需求,支持全自动化数据上传,可充分利用带宽,帮助用户快速上传、下载海量数据。
同时,利用fastone自主研发的分段上传、高并发、断点续传等数据传输技术,优化海量数据的传输效率。
实证小结
1、LS-DYNA任务能够在云端有效运行,大幅提升求解效率;
2、匹配合适类型云资源,LS-DYNA应用的高效率并行性在云端同样适用;
3、fastone的DM工具为用户提供了简单有效的云端数据传输方案,同时无需改变用户本地使用习惯;
4、fastone能有效进行资源的统一管理和监控。
本次CAE行业云实证系列Vol.8就到这里了。
下一期的CAE云实证,我们聊COMSOL。
请保持关注哦!
- END -
我们有个为应用定义的计算云平台
集成多种应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送200元体验金,入股不亏~

更多电子书
欢迎扫码关注小F(ID:imfastone)获取

你也许想了解具体的落地场景:
揭秘20000个VCS任务背后的“搬桌子”系列故事
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
关于为应用定义的云平台:
2小时,账单47万!「Milkie Way公司破产未遂事件」复盘分析
高情商:人类世界模拟器是真的!低情商:你是假的……
【2021版】全球44家顶尖药企AI辅助药物研发行动白皮书
EDA云平台49问
国内超算发展近40年,终于遇到了一个像样的对手
帮助CXO解惑上云成本的迷思,看这篇就够了
花费4小时5500美元,速石科技跻身全球超算TOP500