对广大半导体设计公司而言,算力资源规划和现金流之间的平衡,啧啧,是一门艺术。
多一分是浪费,少一分则崩溃。我们曾经在初创型IC企业必备白皮书和成长型IC企业必备白皮书里分别画过以下两张图:
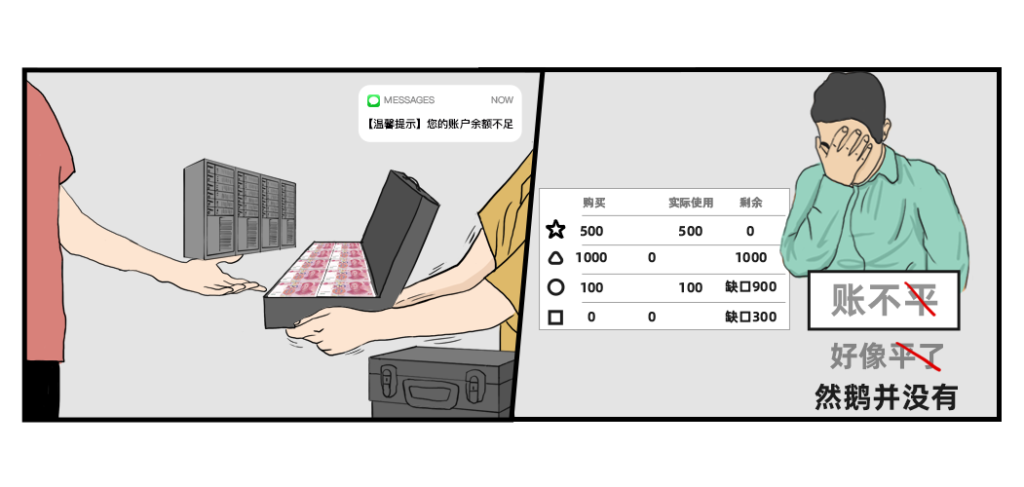
左图名字叫做:守护现金流
这年头现金流的重要性,不必多说。
右图名字叫做:人生就是一场豪赌
不管是初创IC设计公司还是成熟公司,新开始一个项目,总是面临着前路未知的情况:
1. 周期性存在突发算力高峰需求,涉及到先进制程问题更加显著;
2. 每次调整制程,都面临新的资源预估,永远估不准;
3. 可能需要某些内部不可用的内存和计算资源。
我们今天认真盘一盘,怎么把这门艺术拉下神坛。

先给大家一个直观感受。
下图是我们某客户全生命周期月度算力实际用量曲线:整个芯片项目全流程为18个月,涉及前端、验证、后端三大团队。
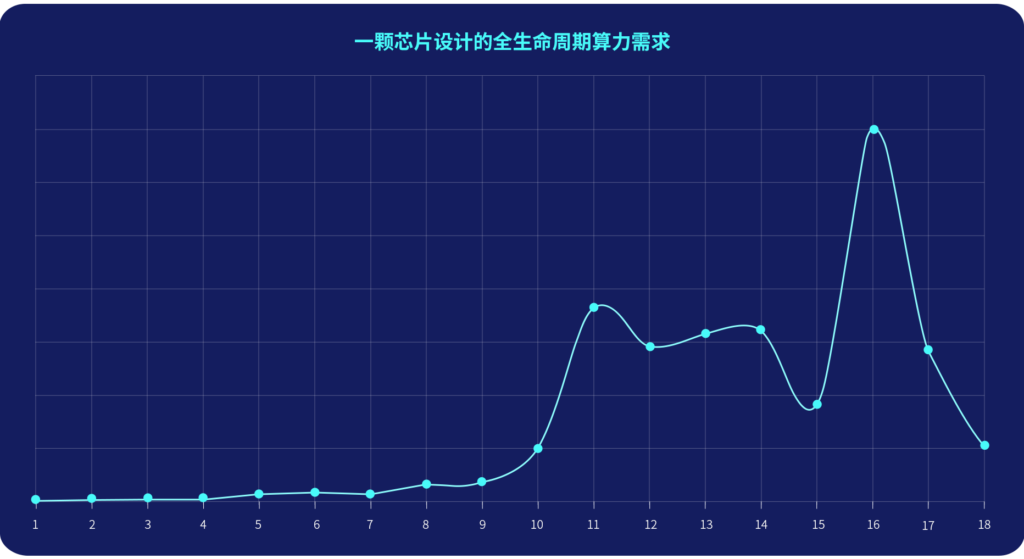
1. 前4个月,只涉及到前端布局与架构,对于算力需求不高,因此月度算力需求较少;
2. 从5月开始,前端、验证、后端均开始工作,算力开始逐步提升,第11个月达算力小高峰,在第16个月达算力最高峰,月度调度峰值达到百万级核时以上;
3. 算力波峰和波谷的核数差距在20倍以上;
4. 算力在第16个月达到最高峰后,迅速下降。
下面我们手把手教你怎么把算力规划拉下神坛:
Part 1 小白版算法
Part 2 老司机版算法
Part 3 全年现实算力需求折算
Part 4 一个并不艰难的选择
Part 1 小白版算法
针对的是:项目全新,团队人员也比较新,需要从零计算
Part 2 老司机版算法
针对的是:项目全新,但有类似经验的老人在团队,可以凭经验值估算
PS:Part 1和Part 2 二选一阅读即可
为了简化计算,我们根据现实情况作以下假设:
1. 研发团队总人数为100;
2. 团队分为前端、验证和后端3部分,人数比值2:1:1;
3. 芯片的全周期分为3个阶段,每阶段4个月 (仅适用小白版算法);4. 三个团队主要使用资源类型:前端团队使用计算型机器;验证团队前期使用计算型机器,之后使用内存型机器;后端团队使用内存型机器 。
Part1 :小白版算法
这套小白版算法是我们根据N家客户的实际情况,得出的经验参考值:包括不同阶段,不同团队的人员配比与人力占用比例,每人job数,每人每job峰值核数。
因实际团队并非全程在此项目中,部分阶段人力需折算,即人力占用比例。
在我们的参考值基础上略做调整,大家就能大致得出自己公司的相应数值啦。
这套算法通过估算不同阶段内、各个团队所需的算力峰值之和,得出每阶段的算力峰值。各团队的峰值计算公式为每人每job峰值核数(多台机器则为每台核数*机器数)*团队人数*每人job数(每个阶段计算方式一致)。
Stage 1:前期阶段(第1-4个月)
① 阶段工作详情:前端从事设计相关工作,验证团队同步参与,工作状态都较为稳定,此阶段每月峰值核数趋于一致;
② 涉及团队:前端、验证团队;
③ 资源并发需求:前端团队每人1台10核、验证团队每人1台20核。
该阶段峰值核时计算(计量单位:核小时):
1月:10核*50人*1job=500
2-4月:前端团队峰值核数=10*50*1=500 ;
验证团队峰值核数=20*25*1=500;
峰值核数总计为500+500=1000;
则该阶段的峰值核数在2-4月,为1000
(下同,不再详述这一计算过程)
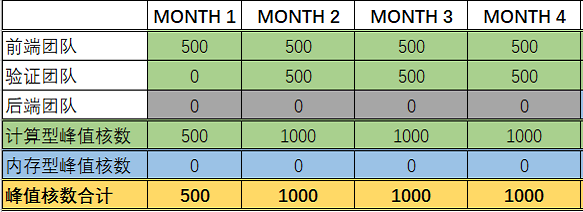
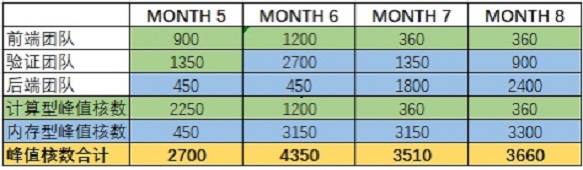
Stage 2:中期阶段(5-8月)
① 阶段工作详情:涉及到前端仿真、验证和部分模块的版图工作。6月在前仿最后阶段做一次大仿真,是算力小波峰,随后算力下降;
② 涉及团队:前端、验证和后端团队;
③ 资源并发需求峰值:
5月:前端团队每人1台18核节点,每人1个job;验证团队每人4个job,每个job约18核(人力占用比例:75%);后端团队每人1台18核节点;
6月:前端团队每人1台24核节点,每人1个job;验证团队每人6个job,每个job约24核(人力占用比例:75%);后端团队每人1台18核节点;
7月:前端团队每人1台18核节点,每人1个job(人力占用比例:40%);验证团队每人3个job,每个job约18核;后端团队每人1个job,每job约4台18核节点;
8月:前端团队每人1个job,每个job18核(人力占用比例:40%);验证团队每人2个job,每个job18核;后端团队每人1个job,每个job约4台24核节点。
计算结果如下
Stage 3:后期阶段(9-12月)
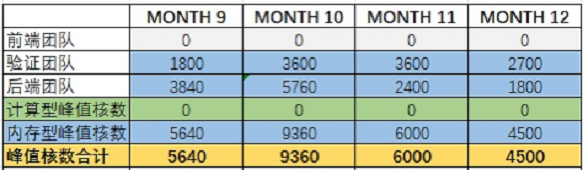
① 阶段工作详情:主要涉及后端仿真相关工作;
② 涉及团队:验证和后端团队;
③ 资源并发需求:
9月:验证团队,每人4个job,每个job约18核;后端团队每人1-2个job,每个job约4台24核节点(后端人均完成1.6个job,取值1.6);
10月:验证团队每人6个job,每个job约24核;后端团队每人1-2个job,每job约6台24核工作节点(后端人力占用比例:80%,每人2个job);
11月:验证团队每人6个job,每个job约24核;后端团队每人1个job,每job约4台24核工作节点;
12月:验证团队每人6个job,每个job约18核;后端团队每人1个job,每job约3台24核工作节点。
计算结果如下
最终全生命周期算力需求图如下(计量单位:核小时):

可以看出:
1. 和文章开头的实际用户算力曲线趋势一致;
2. 不同月份间的峰值算力差异很大,能达到20倍左右;
3. 不同团队在不同月份的峰值算力需求差异明显。
Part2 :老司机版算法
如果对于未来芯片项目,你们有过来人能预估出不同团队不同阶段的算力需求,这套老司机版算法将完全适配你。
这套算法是我们根据有项目经验的芯片研发团队的实际情况,通过填入各月每job峰值核数、每月最大并行job数,计算出各团队每月所需的算力峰值。
下面为大家奉上这份《XXX芯片项目-资源需求调研模板》:

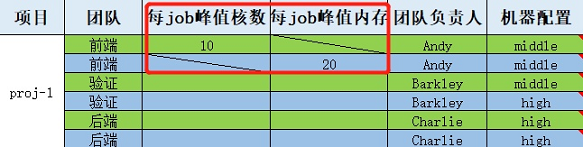
左边项目为不同的项目团队。项目团队内部可分为:前端、验证和后端组。
Step 1:将不同组、每个job所需核数或内存的峰值需求,依次填入中间的“每job峰值核数”和“每job峰值内存”栏目下,负责人填入“团队负责人”栏目下
例如:每个job需要的峰值核数为10,每个job需要峰值内存为20(据经验值统计),前端负责人为Andy。
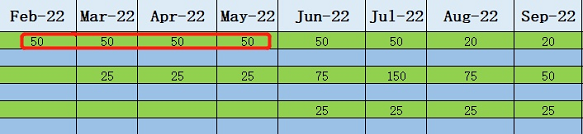
Step 2:在每月栏目下,填入各团队预期的每月并行最大job数(简称:job数)
Job数可根据研发内部统计,也可根据job数=每人最大并行job数*人数进行计算,如团队并非全程在此项目中,人力还需折算统计。
例如:2022年2-5月,前端团队每人最大并行job数为1,团队有50人,均100%投入在此项目中,则填入下表的job数均为:50*1*100%=50。
Step 3:计算各团队当月峰值算力并相加,得出峰值算力总计(计量单位:核小时)
各团队的峰值计算公式:每job峰值核数*job数(每个阶段计算方式一致)。
例如:2022年2-5月,前端团队的每job峰值核数为10,job数为50;2月验证团队还未开始任务,3-5月,验证团队的每job峰值核数为20,job数为25;2-5月,后端团队还未开始任务。
计算过程如下
前端团队:2-5月:10*50=500
验证团队:3-5月:20*25=500
将各团队每月算力峰值相加,得到每月项目的算力峰值,计算得出项目各月算力峰值表
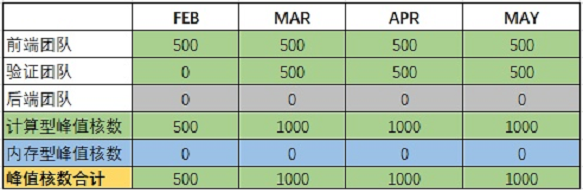
《XXX芯片项目-资源需求调研模板》Server一栏的Middle /High 型是用户自己设定的不同机器配置,后期计算不同机型费用时会用到,跟算力需求计算无关。
Part3 :全年现实算力需求折算
不管是小白版算法还是老司机版算法,都是一个月每天全部按峰值需求跑任务的前提下进行计算的。但实际情况下,肯定不需要一直按峰值顶格跑。
我们折算一下:
全月全资源峰值用量:峰值核数*30天*24小时
全月实际用量可能是:峰值核数*22天*8小时
用小白版算法的数据来调整:
6月算力小波峰:后端按30天*18小时估算,验证按30天*16小时估算;
10月算力大波峰:后端按30天*24小时估算,验证按照30天*16小时估算。
得出下表,并绘制成相应曲线图:

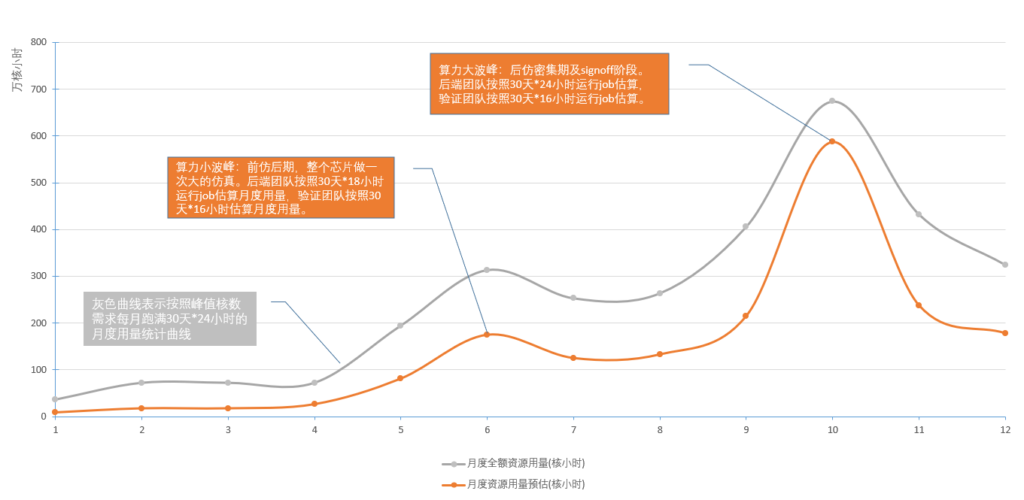
灰色曲线为按峰值计算的算力需求
橙色曲线为折算后实际需要的算力
Part4 :一个并不艰难的选择
好了,全生命周期算力需求算完了。到了算账的环节了。

灰色代表当月按峰值顶格算的用量,橙色代表月度实际用量。
绿色代表本地资源,必须按这一阶段需求峰值准备,也就是按灰色来准备。买不到峰值,肯定会影响到芯片项目进度。
如果是纯本地,就是按绿色这根线买。现金流是必须要动用一大笔的了,采购周期也是必须要考虑的。
按照本文开头我们某客户全生命周期月度算力实际用量曲线,波峰、波谷间差距可高达20倍,月调度核时峰值能达到百万级以上。顶格买……
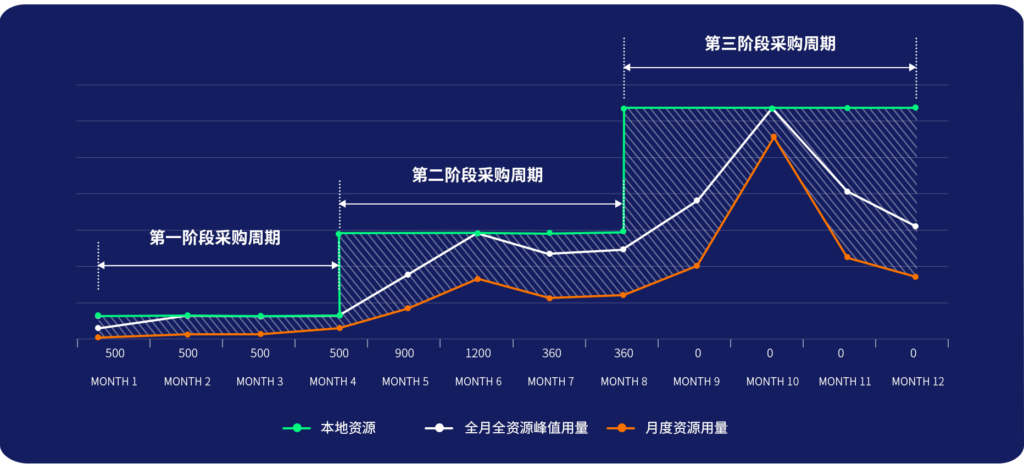
如果是全云端,就是按橙色这根线花钱。想用就用,不想用就关掉,用了才花钱。现金流逐步平缓支出。
绿色线和橙色线中间的差距(图中阴影部分),各人可能有各人的体会。
算力资源规划VS现金流
芯片项目周期VS市场竞争格局
具体怎么权衡和取舍,还是要看企业自己。
一颗芯片设计完整生命周期下,不同阶段,不同应用场景,对算力更精细的需求差异,我们相应的推荐和建议,以后再聊。
- END -
我们有个为应用定义的EDA云平台
集成多种EDA应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送300元体验金,入股不亏~
现在!我们的IC设计研发云平台支持免费试用,还送200元体验金扫码免费试用~

如果你对这个一站式IC设计云平台还有更多想问的,比如:
1、你们支持哪些EDA应用?能覆盖到我常用的软件吗?
2、EDA应用所需的计算资源非常大,你们如何解决这个问题?
3、把EDA研发环境部署到云上有什么好处?
4、除了CPU,GPU/TPU/大内存的机器都有吗?
5、你们说的“一整套即开即用的IC研发设计环境”是什么意思?从本地到云上,操作方式会改变很大吗?
6、云端输出计算结果是否与本地完全一致?
7、云端这么多的机器,管理得过来吗?
8、云上有些资源很贵,有没有节约成本的方案?
9、任务监控也能用来省钱,你们是怎么做到的?
10、很多PDK,就有几十T,怎么到云上,而且需要持续更新?
11、如何云上保护我们的IP资产?
12、脚本每日都有变动,云上要增加工作量?工作脚本如何更新?
13、云上的EDA软件怎么部署安装?
14、License Server配置在本地和云端对计算性能/一致性/稳定性是否有影响? 15、使用平台的工作人员比较多,能否对每个人设置使用资源的上限?
16、公司有海外研发部门,用你们平台方便吗?
17、怎么保障数据安全?
……答案都在这里,欢迎扫码添加小F微信(ID:iamfastone)免费获取~

关于为应用定义的云平台:
续集来了:上回那个“吃鸡”成功的IC人后来发生了什么?
这一届科研计算人赶DDL红宝书:学生篇
缺人!缺钱!赶时间!初创IC设计公司如何“绝地求生”?
速石科技获元禾璞华领投数千万美元B轮融资
一次搞懂速石科技三大产品:FCC、FCC-E、FCP
速石科技成三星Foundry国内首家SAFE™云合作伙伴
EDA云平台49问
国内超算发展近40年,终于遇到了一个像样的对手
帮助CXO解惑上云成本的迷思,看这篇就够了
花费4小时5500美元,速石科技跻身全球超算TOP500