

LeDock是苏黎世大学Zhao HongTao在博士期间开发的一款分子对接软件,专为快速准确地将小分子灵活对接到蛋白质而设计。
LeDock优于大部分商业软件,在Astex多样性集合上实现了大于90%的构象预测准确度,对接时间最快仅需三秒。
LeDock同时支持Windows、Linux和MacOS三大操作系统。
Linux版支持大规模虚拟筛选,需要通过代码操作才能实现目标。
Windows版的图形界面极大简化了药物化学家常见多重复杂的对接过程,但每次任务只能对接一个分子,效率极低,只适用于少量对接场景。
如果考虑到不少用户还有分子库相关的需求,无论哪种版本,对用户来说,都有点难搞。
今天我们就通过一个LeDock实证来聊聊,怎么帮助大家愉快地(不写代码)提高大规模分子对接效率(少点手动),甚至还能解决一些别的问题(一些爽点),扩大实验的空间和范围,放飞研发人员的想象力。
科研这件事,还是需要有点儿想象空间的。
用户需求
某药企药物化合部想使用LeDock进行20万分子对接任务,但本地只有两台48核的工作站。
如果按Windows版的一对一串行对接模式,假设按1分钟一个算吧,不吃不喝不睡不关机,也要对接138天。如果再加上中间出错修改、参数配置、分子库处理,无数次重复手动操作步骤,就,没法算了。。。
如果用Linux版,这一时长就取决于两个点:本地拥有的资源数量和IT能力的高低。
所以,他们有以下几个问题:
1. 基于现实条件,怎么快速达成用LeDock跑20万分子对接任务这个目标?
2. 能不能使用更友好的图形界面来进行操作?甚至把一些工作流程固定,下次直接就能用,还可以分享给同事?
3. 能不能帮忙准备分子库?
实证目标
1、能否让用户拥有Windows版和Linux版的双重优点,不用写代码,也能实现大规模虚拟筛选?
2、LeDock任务能否在fastone云平台大规模运行且效率显著提升?
3、用户很多常见复杂的手动操作,能不能自动化进行?
4、是否能为用户提供开箱即用的分子库?
实证参数
产品类型:
速石FCC-E产品
操作系统及应用:
LeDock Linux版
适用场景:
研究配体和受体(药物分子)相互作用的模拟方法
云端硬件配置:本任务属于CPU密集型任务,对内存的需求不高,因此我们选择了高性价比的云端计算优化型实例(CPU/内存=1:2)。
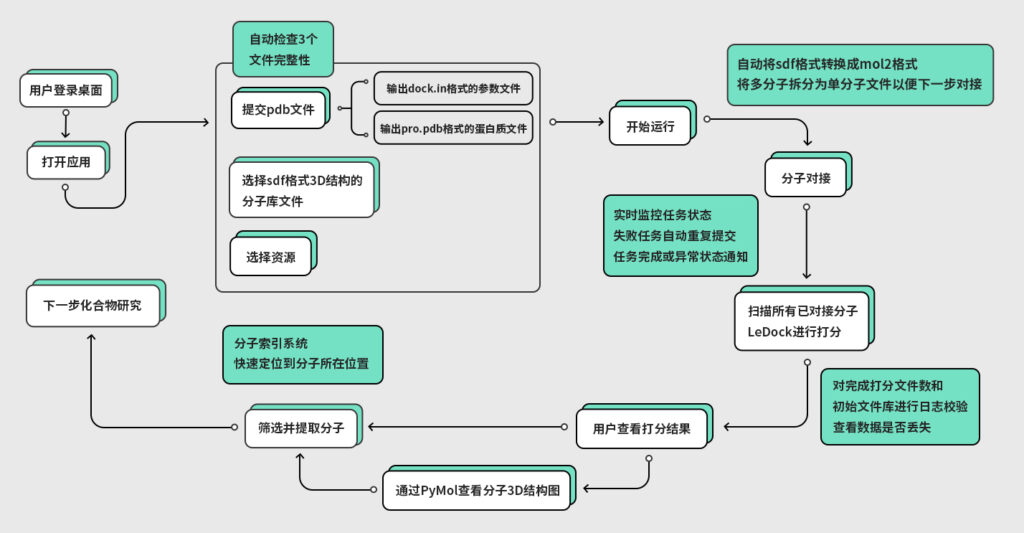
用户完整工作流程图
用户打开应用,提交蛋白质pdb文件,选择分子库文件和资源后,由fastone平台进行分子对接并打分,用户可直接查看结果,提取目标分子,进行下一步化合物研究。
实证过程
一、开箱即用,一键定位&加密的分子库
1. 开箱即用的分子库
对接开始前,用户除了蛋白质pdb文件,还需要准备分子库文件。分子库大多来自海外,其本身的大小和数据质量,直接影响着后续虚拟筛选阶段的命中率。对用户来说,需要将分子库从外网下载到本地,有些数据量动辄几十T,如果还涉及分子结构从2D转换到3D等复杂处理,运算量相当大,要么耗时间,要么耗钱。
我们已经准备好开箱即用的分子库供用户使用,包括:Zinc、DrugBank、Maybridge、Enamine等。
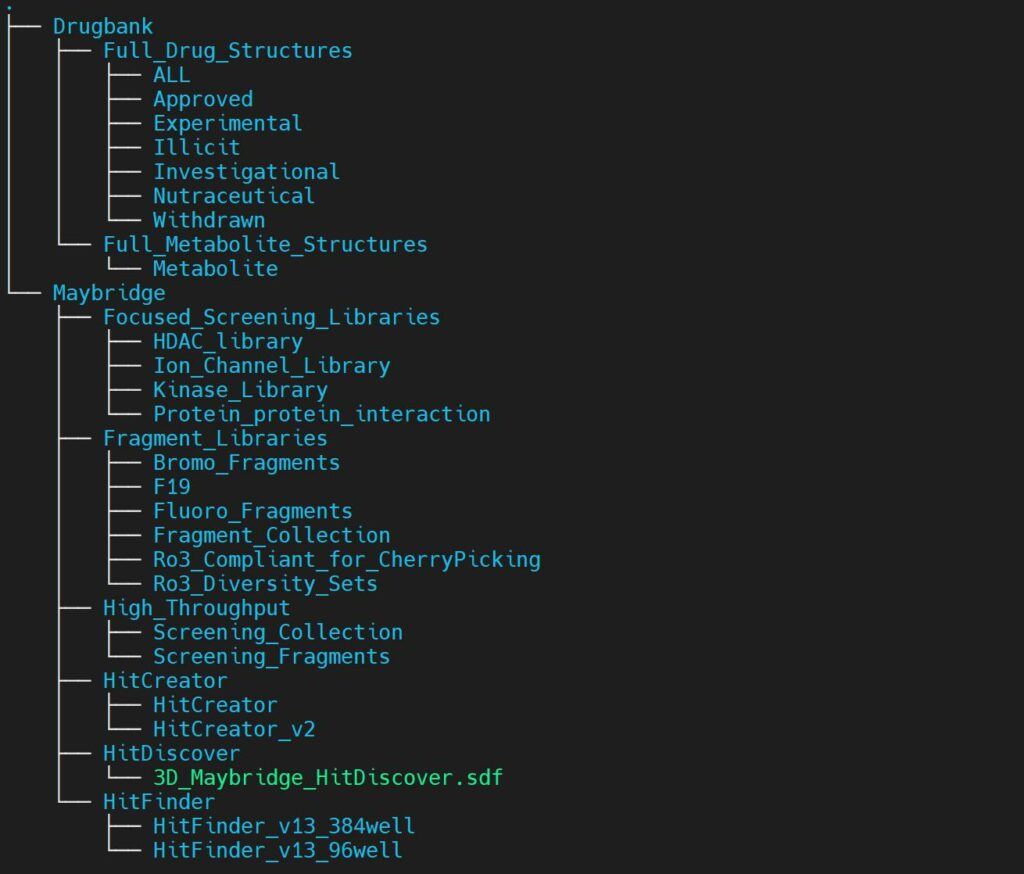
因为LeDock仅支持mol2格式,fastone平台会在对接前,自动将sdf格式转换成多分子mol2格式文件,同时完成拆分,使单个分子对应一个mol2文件。否则,直接把多分子mol2文件放进去对接,只会读取第一个分子。
2. 一键定位&加密的分子库索引系统
用户筛选完分子后,还要在20万个分子的原始库里迅速定位并提取出来。这难度不亚于只知道书名但要在图书馆里找书,茫茫书海,大海捞针。
我们的分子库索引系统就派上了大用场。
这套索引和图书馆索引系统类似,将原始分子名字通过加密转换成唯一ID, ID相当于GPS定位,表示该分子在原始库里的具体位置。
比如,某分子的唯一ID为“A-G22-18578”,即表示他位于分子库A区G22柜的第18578个,可以轻松将分子提取出来。

这道索引系统相当于为原始分子库做了一道数据加密和定位系统,除了用户没人知道最终提取出来的是哪些分子,既保护了数据的安全性,又让用户能迅速定位到某个分子。
二、云端大规模业务验证
200000个分子上云
用户使用fastone平台,在云端调度768核计算资源,成功对接200000个分子,从中筛选出了300个分子,进行下一步的化合物研究。此次任务对接共耗时3.5小时,平均对接一个分子只需45S。
这里要说明一下,这个45S不是纯分子对接时间,是包括了用户的整个工作流程所有操作在内的。而且,不同分子之间的对接时长是不一样的,时间会被对接得慢的分子拉长,无法直接横向对比。比如用户在进行3万分子对接的时候,平均时长却达到了90S。
实证过程:
1. 云端调度48核计算优化型实例运算一组LeDock任务(对接约200000个分子),耗时3262.6分钟;
2. 云端调度96核计算优化型实例运算一组LeDock任务(对接约200000个分子),耗时1630.8分钟;
3. 云端调度192核计算优化型实例运算一组LeDock任务(对接约200000个分子),耗时815.1分钟;
4. 云端调度384核计算优化型实例运算一组LeDock任务(对接约200000个分子),耗时407.2分钟;
5. 云端调度768核计算优化型实例运算一组LeDock任务(对接约200000个分子),耗时203.3分钟。
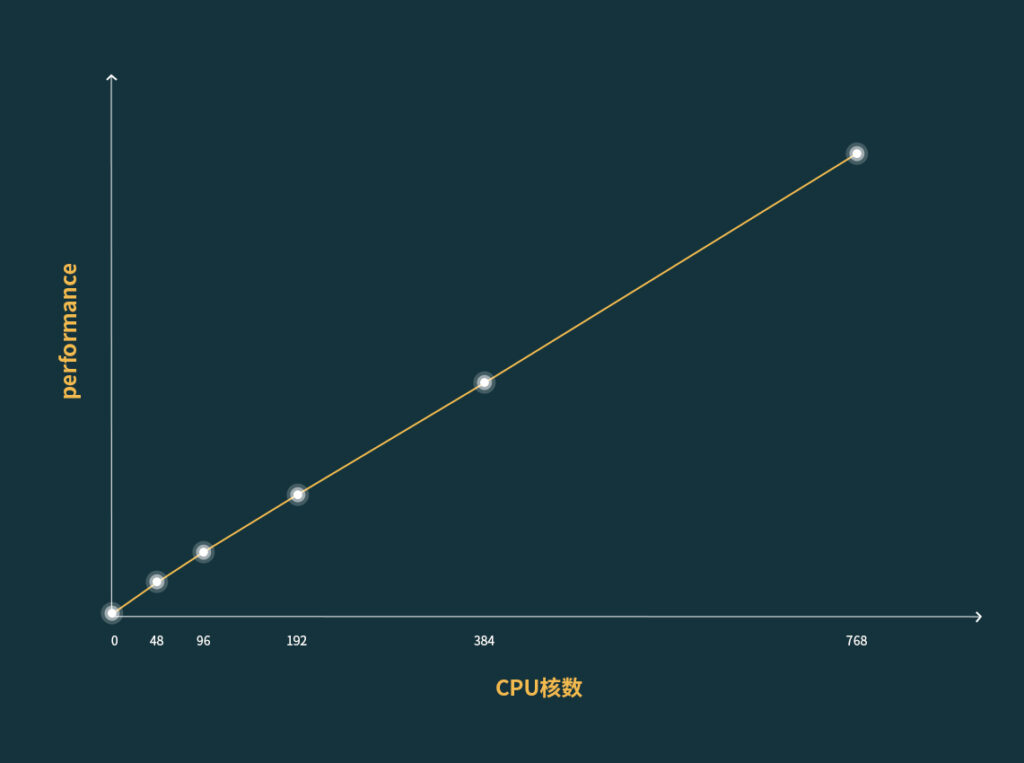
从图上可以看出,LeDock任务在云端的线性扩展性表现良好,当云端资源增加到768核之后,运算时间缩短到了3个多小时,极大地提升了运行效率。
即使当分子数量增加到2800万这个量级,我们调用10万核CPU资源,在AutoDock Vina这个应用上也同样表现优秀,可参考《提速2920倍!用AutoDock Vina对接2800万个分子》
三、自动,自动,全是自动
1. 单机模式VS并行化
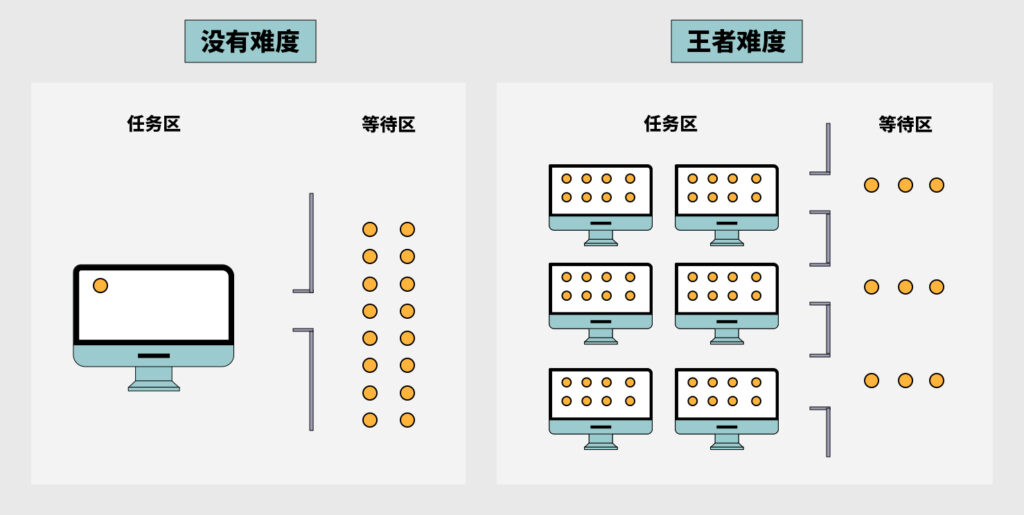
我们把跑分子对接这个任务分成三种不同的IT难度等级 :
没有难度:单机单CPU核,单任务。
中等难度:单机多CPU核,多任务。
王者难度:多机多CPU核,多任务。
想要对三种难度等级深入了解,看这里《揭秘20000个VCS任务背后的“搬桌子”系列故事》
如果按照“没有难度”这个等级,200000个分子串行排队,一个任务跑1分钟,我们开头已经算过了,基本没什么现实可操作性。
我们直接将你带飞到"王者难度",在n台n核的机器上跑,效率提升n*n倍,理论上n可以无限大。这个数字用户可以自行设定。
2. 一次设定,跑完20万个任务
怎么把一些工作流程固定,不用一次次重新设定,下次直接一键使用。甚至还可以分享给其他同事,提高大家的工作效率?
到了速石传统艺能项目—自定义模板出马的时候了。
我们将用户跑LeDock的工作流程固定成一套模板:
step 1:用户提交蛋白质pdb文件;
step 2:用户选择sdf格式分子库文件;
step 3:fastone平台自动将sdf格式转换为mol2格式分子库文件;
step 4:fastone平台自动进行多分子拆分;
step 5:fastone平台将蛋白质、参数文件与mol2格式分子进行对接;
step 6:fastone平台扫描所有已完成对接的分子,进行打分;
step 7:用户查看打分结果;
step 8:用户筛选并从分子库里提取出分子,进行下一步化合物研究。
用户在这个模板的基础上,自行调整各项参数,就能按这个流程一路跑下去了。
一次设定,反复使用,省时省力,还不用担心以后不小心出错。
这套自定义模板不但能分享,还可以跨应用设定,可以展开看看《1分钟告诉你用MOE模拟200000个分子要花多少钱》
3. 自动检查文件完整性
这个自动检查包括两个部分:
第一,用户上传配置文件的同时,速石平台内置的检查程序,会自动检查文件完整性。
每个步骤需要用到的文件量很可能不一致,如果用户运行到第五六步了,才发现某个上传文件有问题,应该会非常崩溃。
第二,对接完成后,我们会对完成打分的文件数和初始文件库做日志校验,看数据是否有丢失。平常情况下,用户可能很难察觉。
在这种大规模任务下,自动检查程序能大大降低用户任务返工率,以及协助用户判断运行过程中是否有问题。有些问题靠人力可能无力检查。
4. 两种场景下的重复提交任务功能和自动监控告警
放着机器通宵跑任务时总会幻想:第二天一早,任务已经跑完了,完美。
现实是:任务才跑了10%。
任务出错,进度条卡住,可能会有两种情形:
第一种:每个任务之间独立,彼此没有关联。
一般任务数量越多,失败的任务数量大概率也会变多,比如对接1万个分子,有可能会有50个失败任务;20万个分子,可能有1000个失败任务。
第二种:每个任务间有明确的先后处理顺序,必须从A任务按序跑到Z。
假如到F任务就失败了,整个任务就此停滞,凉凉。
自动检查任务状态并对失败任务及时重复提交的功能,就是这种场景的克星,尤其是第二种,不然等待着你的,大概就是通宵,同时睁大你的双眼了。我们的任务监控告警功能,还会时刻监控任务状态,通过IM及时通知用户,任务出现异常或已经完成。
我们还见到过一种特殊情况,Amber用GPU跑任务速度快,CPU较慢,但使用GPU计算时存在10%-15%的失败概率。一旦任务失败,需要调度CPU重新计算。
能否及时且自动地处理失败任务,将极大影响运算周期。如果想了解我们怎么应对的,请点击《155个GPU!多云场景下的Amber自由能计算》
实证小结
1、LeDock 大规模云端筛选毫无压力,运行效率呈线性显著提升;
2、fastone平台能提供开箱即用,且能一键定位&加密的分子库;
3、fastone 能为用户定制自定义模板,一次设定,反复使用,界面友好;
4、fastone平台提供的自动化检查程序和重复提交任务功能,极大降低用户的工作量;
5、用户在20万个分子对接任务中,筛选出了300个分子,进行下一步的化合物研究工作。
本次生信行业云实证系列Vol.12就到这里。
关于fastone云平台在其他应用上的表现,可以点击以下应用名称查看:
HSPICE │ Bladed │ Vina │ OPC │ Fluent │ Amber │ VCS │ MOE │ LS-DYNA │ Virtuoso│ COMSOL
- END -
我们有个生物/化学计算云平台
集成多种CAE/CFD应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送200元体验金,入股不亏~

更多电子书 欢迎扫码关注小F(ID:imfastone)获取

你也许想了解具体的落地场景:
这样跑COMSOL,是不是就可以发Nature了
Auto-Scale这支仙女棒如何大幅提升Virtuoso仿真效率?
1分钟告诉你用MOE模拟200000个分子要花多少钱
LS-DYNA求解效率深度测评 │ 六种规模,本地VS云端5种不同硬件配置
揭秘20000个VCS任务背后的“搬桌子”系列故事
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
关于为应用定义的云平台:
Uni-FEP on fastone|速石科技携手深势科技,助力创新药物研发提速
【大白话】带你一次搞懂速石科技三大产品:FCC、FCC-E、FCP






