
我们在今年年初的文章 【2021版】全球44家顶尖药企AI辅助药物研发行动白皮书 - 速石科技BLOG (fastonetech.com) 白皮书里有聊到,对于AI,我们的判断是现在主要还集中“人工”的部分,而不是“智能”。但CADD(计算机辅助药物研发)/AI通常可以支持达到或选择这些药物研发工作的“更好”起点。
a16z的Vijay Pande博士在上周写的文章《AI is Too Dumb… For Now》,同样认为现阶段的AI还是太“笨”了。如果人工智能不能变得比现在“聪明”很多,它在生物领域的潜力将是有限的。
Vijay Pande博士,a16z普通合伙人,主要专注于生物制药和医疗领域的投资。
此前,Vijay是斯坦福大学的 Henry Dreyfus 化学教授,结构生物学和计算机科学教授,开创并一直在推动计算机科学技术在医学和生物学领域的应用。他拥有300多篇出版物,两项专利,两种新型候选药物。
那么,如果想要让AI更加“聪明”,数据上,算法上,具体应该怎么做呢?
用“AI inside”替代“Intel inside”,对企业来说又意味着什么?
我们看看他怎么说的:
为了证明AI在生物领域的应用价值,我们走了很长一段路。
2018年,我还在《纽约时报》上争辩:考虑到医生的大脑很大程度更是黑匣子的前提下,围绕医学中人工智能“黑匣子”的恐惧到底有多不合理,以及未来的障碍和机会可能在哪里。
(注:这个争辩背景是,有人提出没有人知道那些高级AI算法到底是怎么学习的,过程过于黑箱,令人害怕。而Vijay说其实人类做决策很多时候是出于直觉,也不一定能说清背后的逻辑推理过程,本质上是个更大的黑箱。)
今天,已经有大量证据表明AI能掀起医疗和生命科学领域的革命(更不用说其他领域),甚至在一度被认为过于复杂而无法通过算法处理的一系列任务上表现得超越人类。
但是,尽管有了这些证据,现实中的现实是:如果人工智能不能变得比现在更智能,它在生物领域的潜力将是有限的。
AI可以被训练(很像狗),但不能真正理解;它可以玩游戏,但仅限于已知规则;总之,它无法超越训练本身。
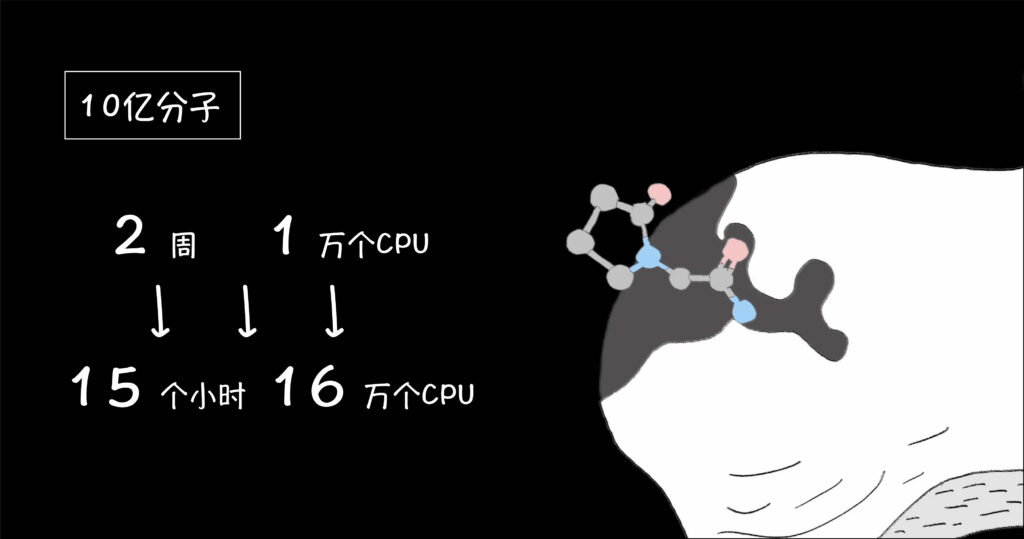
拿识别与致病蛋白质结合的小分子为例,人工智能能够超出人类能力地加速和扩大药物发现范围,它必须从给定的训练数据中推断出物理规律(比如原子可以堆积多近)、化学规律(比如不同化学键的强度)和生物学规律(比如蛋白质口袋的灵活性)。但如果在任何方向上数据量过小,就会导致毫无意义的结果。 哈佛大学医学院使用自研的VirtualFlow云平台调用16万核CPU对接10亿分子花了15小时:《15小时虚拟筛选10亿分子,《Nature》+HMS验证云端新药研发未来 - 速石科技BLOG (fastonetech.com) 》
需要明确的是:我们所讨论的不是一些类似于人类的科幻人工智能概念,也不是只有生物学才需要面对的“笨”人工智能挑战。但是,由于需要大量行业专业知识才能理解问题的根源和提出可能的解决方案,在生物和医疗领域最能感受到依赖于这些朴素算法带来的影响。
如果我们想在生物学和医疗领域更有意义地应用人工智能,并取得真正的进步,我们需要能够创建具备行业专业知识的更“聪明”的AI算法。
那么,怎么才能做到呢?
对这个领域的玩家意味着什么?
一切从数据开始……
房地产行业的至理名言是“location,location,location”,而在人工智能领域,永远是“数据,数据,数据”。
然而,现在的数据不太适合AI在生物学中的实际应用。探索这些数据可以得到一些零散的信息,但没法得出普适性的生物学洞察。而且,这些数据也缺乏对AI学习内容和方向上的控制,无法避免数据缺陷。
为了让人工智能在生物和医疗领域得到更实际和更广泛地应用,需要通过自动化的方式生成数据。自动化的好处在于:更系统化,更可重复,不受人类情感约束,比如过于重复过于无聊。
但更关键的点在于如何设计实验,需要在一开始就有针对性地为AI提供数据,从而确保更高质量的数据,规避数据缺陷。AI应该在开始数据收集之前就介入,这样能更好地进行实验设计,确定实验路线。但很多时候,AI往往是在实验快要结束的时候被硬塞进来的。
这跟科学家们之前受过的训练完全不同,以前的实验目标往往是验证一个特定假设,而现在因为AI极大地扩展了可能性,为我们开启了新世界的大门,让我们可以拥抱那些我们不知道我们不知道的现实。
还是拿识别与靶标蛋白质结合的小分子为例(在初创公司和制药企业中越来越常用的应用场景):
一方面,AI可以变得特别强大,尤其是当结果信息可以汇总,加强原来的数据,开始新一轮学习;
另一方面,AI可能会选择一些违反科学家直觉的分子。以前,药物化学家会根据经验,对哪些修改会提高亲和力和选择性下一系列赌注,通常会排除他们“知道”行不通的选择。而除了需要在计算机上进行大量天文数字模拟计算之外,AI不需要排除任何可能的修改,从而帮助药物化学家扩大探索范围,选择应该制造和测试的分子。
这里就有一个虚拟筛选海量分子的案例,我们调用了10万核CPU资源,花了15小时搞定了2800万个分子:《生信云实证Vol. 生信分析上云案例, AutoDock Vina分子对接虚拟筛选 (fastonetech.com)

这就是人工智能的力量——超越人类所能做的。当然,前提是它是“聪明”的,而不是“笨”的。
所以,到底如何让AI更智能呢?
除了更高质量的数据,我们显然还需要更优秀的算法。
1.升级算法
学弹吉他是件有挑战性的事情,但对于会弹钢琴的人来说则要容易得多(因为他们已经会看乐谱、操作一种乐器以及对音高和音调有敏感性)。我们可以将学钢琴当成学吉他的“预训练”。而在生物领域,预训练看起来像是一种医学转录算法,在使用医学术语和分类学进行训练之前,先使用英语语言和语法进行训练。预训练为AI提供了大量练习,教会它有关概念之间的关系,并且具有一些明显可见的好处,比如加快以更少输入实现更高准确度这个过程。预训练的缺点是它仍然依赖于AI根据已知数据发现和推断已知规则。
另一种方案是把行业专业知识直接编进算法里。这里的关键是以一种足够通用的方式表示数据,让它可以处理所有不同的排列组合。例如,在自然语言处理中,朴素AI以像素的形式输入数据,然后将其翻译为字母、单词和句子等。使用更智能的编码可以将文本显示为字母,这样可以大大减少训练数据量,为数据贫乏的环境和更可预测的算法打开大门。在生物中,这可能意味着不再以体素(3D像素)的格式向AI描述分子,而是从包含了化学键信息的图形开始,这意味着更大的化学空间。 让数据表示包含更多目标信息是棘手的,必须经过深思熟虑,因为它可能变得非常清楚,也容易滑向反面,变得更加复杂难懂。
2. 面向行业应用而设计
当算法从一开始就面向某个特定生物应用进行设计时,它们也将变得更智能,同时能获得行业专业知识。生物领域使用的很多AI技术都是直接从非生物应用中搬过来的;放射学中的算法与用于基本图像识别的神经网络类型是一样的。
现在我们开始看到了针对生物学问题设计的算法和训练的出现,像自监督算法的变体,它们从通用对应物开始,但结合了生物学见解来帮助学习。例如,了解细胞自然特征(染色质、细胞器等)的细胞成像算法可以让我们更自然地使用自监督方法。这是因为数据更加一致(所有类型都相同,全都是细胞成像),并且图像中的元素在没有高级机器学习的情况下是众所周知的(因为我们了解细胞的基本生物学)。这也将带来更好的整体表现,并降低训练数据量需求。
3.深入结合行业知识
最终,当算法与特定行业的计算方法成功融合时,它们将变得更智能,并提高适用性。
以分子动力学模拟为例,这是一种可以对分子物理和化学的许多方面进行编码的强大计算方法,但它仍然依赖于以临时、有偏见和依赖于人类判断的方式完成的参数和训练。通过将AI融入这些模拟计算中,可以使参数选择更加稳健和可重复,带来方法的整体改进。
在《生信云实证Vol.6:155个GPU!多云场景下的Amber自由能计算 - 速石科技BLOG (fastonetech.com)》中,我们调用155个GPU进行基于分子动力学模拟的炼金术自由能计算。
未来,我们将基于AI模拟整个生物体。
综上所述,所有这些都导致人工智能的“智能”发生翻天覆地的变化——从基于任务的简单训练(类似于训练狗的特定技巧)转变为需要更少训练的更通用的智能,更自然地超出训练本身(在科学范围内),实现更准确的预测。
AI inside……意味着什么?
把“Intel inside”换成“AI inside”,对创业公司和老牌企业意味着什么?生物领域并不是第一个正在适应这种大转变的行业。从华尔街到麦迪逊大道再到硅谷,每个人都在适应AI,我们能看到文化障碍与技术障碍几乎一样高。
对于一家生物公司来说,更实际和更广泛地采用AI意味着将人工智能以及懂人工智能技术的人员将融入每个团队,而不是一个通常在最后才被叫过来了解其他人做了些什么的独立AI小组。这可能意味着企业需要配备在人工智能和生物领域“双语”的人员,以及建立一种重视双方的文化:渴望计算能力的生物学家和深深植根于生物领域的计算科学家。
众所周知,改变根深蒂固的文化非常困难。
初创公司在这方面有明显优势,可以从0开始构建基于AI原生的团队和思维方式。对于老牌企业来说,与其他创新一样,领先的永远是那些能够调整传统模式的公司。当然,他们也可以选择建立全新的以AI为中心的团队,让这些团队承担越来越多的责任,从内部进行瓦解。

一种新的人才即将到来。
过去,“药物猎人”是药物化学家。但是随着可以帮助完成机械重复工作和分子合成的CRO公司的兴起,现在谁制造分子远不如谁设计它们重要。随着“量化分析师”的出现,我们看到金融领域就有类似的转变,这些人更多拥有计算技能而不是对该领域专业知识。同样的,这种转变也将发生在化学和生物实验室里。
到目前为止,这些生物“量化分析师”必须依赖大数据来支持他们的统计方法,由于成本和复杂性,现在还很难落地。但未来的智能算法能将他们的技能应用于小数据——从而应用到公司的所有领域。大数据是基础设施和管线问题;小数据永远是个智力问题,通过智能算法来解决,而不仅仅是靠聪明人。
正是这种能处理小数据能力的智能算法,将使AI无处不在。
与之前的其他重大技术转变一样,从朴素到智能 AI 的转变将重塑整个组织结构,而不仅仅是与其最接近的功能。
为什么?因为更聪明的人工智能可以帮助回答曾经只属于精明的人类判断领域的关键业务问题。
太多人将人工智能视为生物制药进步历史长河中的下一个阶段。
人们很容易把AI当成又一项技术进步,然而,这是一个过于狭隘的观点,因为与其他技术不同,人工智能——尤其是这些智能算法——不仅是解决一个问题的工具,而且是可以应用于所有问题的工具。真正的力量不仅在于将其用作单一工具,还在于使用AI放大和整合公司中的所有工具和技术。
它不仅仅只是摆在桌面上的一个新盒子,而是我们在每个角色中的学徒和盟友。随着人工智能无处不在,它将变得更聪明,我们也是。
我们基于全球44家顶尖药企(包括3家中国药企)在利用AI辅助药物研发上的行动(共涉及55家AI初创企业、12家IT-云服务商、7所高校)制作了《【2021年】全球44家顶尖要求AI辅助药物研发行动白皮书》,有兴趣的可扫码添加小F微信获取。

- END -
我们有个为应用定义的云计算平台
集成多种EDA应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送200元体验金,入股不亏~

更多电子书欢迎扫码关注小F(ID:imfastone)获取

你也许想了解具体的落地场景:
LS-DYNA求解效率深度测评 │ 六种规模,本地VS云端5种不同硬件配置
揭秘20000个VCS任务背后的“搬桌子”系列故事
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
关于为应用定义的云平台:
2小时,账单47万!「Milkie Way公司破产未遂事件」复盘分析
高情商:人类世界模拟器是真的!低情商:你是假的……
【2021版】全球44家顶尖药企AI辅助药物研发行动白皮书
EDA云平台49问
国内超算发展近40年,终于遇到了一个像样的对手
帮助CXO解惑上云成本的迷思,看这篇就够了
花费4小时5500美元,速石科技跻身全球超算TOP500







