2023年开篇——芯片设计五部曲来了!
本季将会包括:模拟IC、数字IC、存储芯片、算法仿真和总结篇(排名不分先后
第一集:模拟IC
模拟IC是负责生产、放大和处理各类模拟信号的电路,工程师通过模拟电路把模拟信号放大缩小后,再全部记录下来,是连续的信号;而数字IC则是通过0和1两个代号来处理手机信号、宽带信号和数码信号等,是离散的信号。
如果说数字IC像科学,那么模拟IC,就更像是一种魔法。
利用计算机来辅助模拟芯片设计,本质是在解一道又一道高阶微分方程题。
EDA工具就是干这个的,ta的价值,就不需要我们来解释了。
而我们今天的主题是:模拟IC设计不同阶段有哪些典型的业务特点,使用的EDA工具有哪些特性,我们如何利用计算机技术提升不同业务场景的计算效率,协助模拟芯片工程师更高效地完成芯片研发工作,提升整体效率。
本篇主要从EDA工具的计算任务视角出发。
而在计算角度之外,调度/管理/数据/协同/CAD等视角,那就是另外的(价钱)篇章了~
先给大家一个模拟芯片设计全流程分析图:
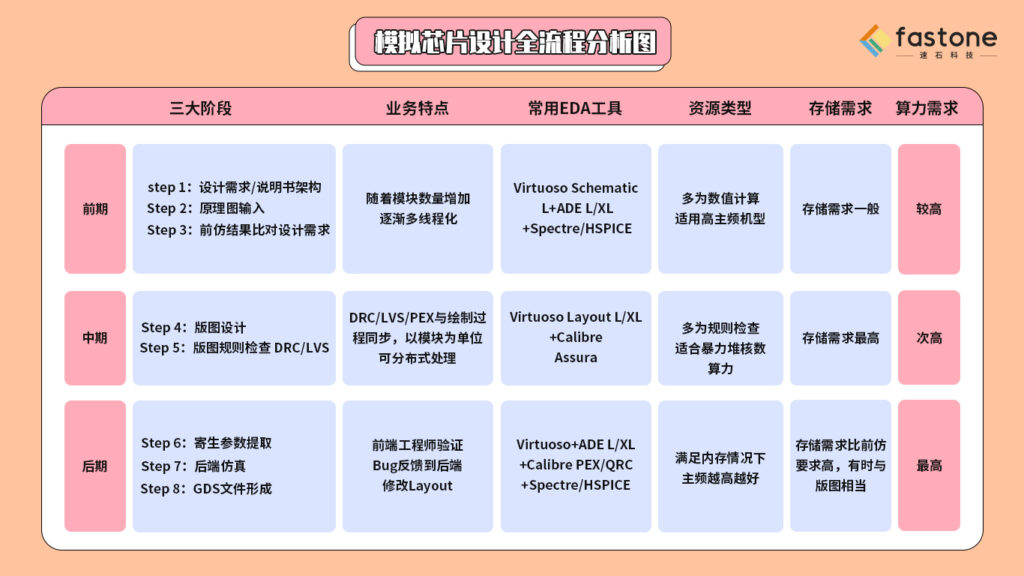
1、前仿阶段:前端电路设计与仿真
本阶段包括了设计需求/说明书架构、原理图输入、前仿结果比对设计需求3大步骤。
前仿阶段本质上是数值计算,因此对主频要求很高,一旦资源无法满足,会直接造成CPU过载,且任务之间独立可切割,十分适合并行。基于设计图的设计与仿真,参数范围较少,对内存要求不高。此阶段多为多corner与蒙特卡罗Monte Carlo任务,峰值算力需求较高,存储需求一般。
2、中期:版图设计验证
本阶段包括版图设计、版图规则检查DRC/LVS两个步骤。版图绘制/验证同属规则检查,因为不涉及数值计算,对主频要求不高,重内存需求。版图可以模块为单位进行切割,子任务间几乎无数据关联、适合并行。但版图检查量十分大,算力需求比前仿高,推荐使用多核+大内存机型,存储要求最高。
3、后仿阶段:后端仿真
后仿包括寄生参数提取、后端仿真、GDS文件形成。后仿和前仿类似,多个任务可进行分布式处理。但后仿阶段任务,因为有可能涉及电磁场仿真,本质虽为数值计算,但需在优先满足内存情况下,再满足高主频需求,因为加入了各类元器件的寄生参数,算力需求是三大阶段里最高的,存储比前仿要求高,有时会与版图阶段相当。
以下,我们选了三种典型场景,展开说说:
两大超常见数值计算场景
多corner又称为多工艺角,和蒙特卡罗Monte Carlo属于两种不同的电路性能与工艺误差的估计方法,但本质上都是数值计算,前仿和后仿都会大量使用这两种方法进行任务处理。这两种方法里的单个任务间都独立、没有数据关联,不论是多corner 还是Monte Carlo都很适合进行分布式并行计算。
推荐阅读:揭秘20000个VCS任务背后的“搬桌子”系列故事
这个故事拆开揉碎地解释了我们怎么帮助用户从单机单任务单线程运行的阶段大幅度跨越到了大规模任务自动化集群化运行阶段,应该能很好地帮助你理解为啥分布式并行计算会大大提高计算效率。
多corner是将元件的电阻、温度、电压等参数的误差上下限固定后,取每个参数的极值(误差上限或误差下限)进行排列组合,每一个组合都是一个独立的任务
一种组合就是一个corner,全部的排列组合即多corner。
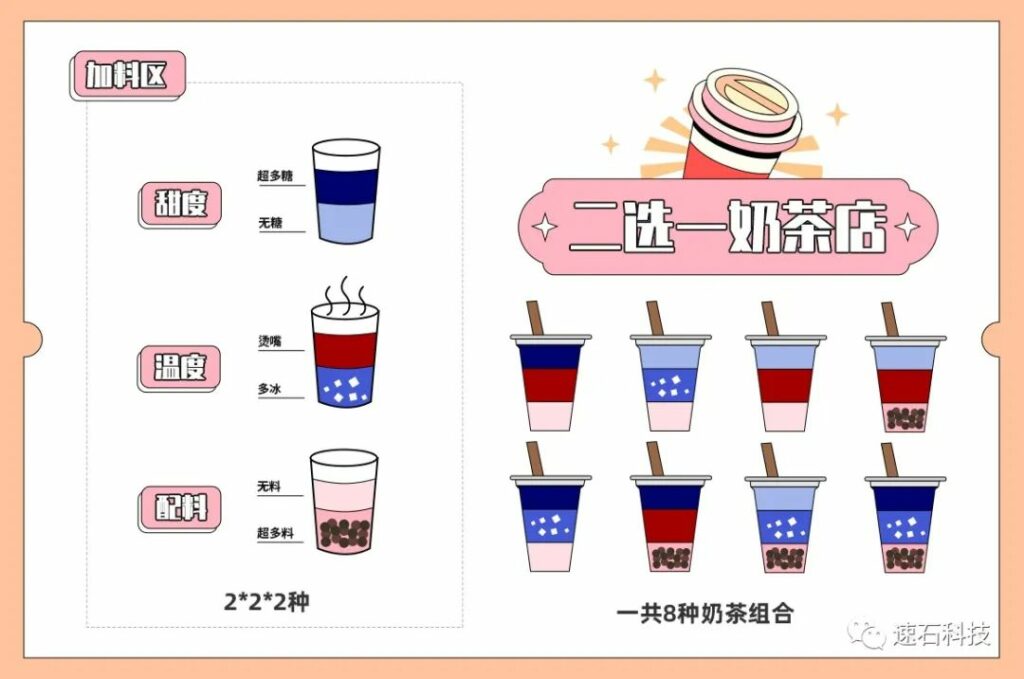
这就像你来到一家二选一奶茶店。这家店奶茶店的甜度、热度、加多少配料都只提供两个选择,你要么选择不甜,要么最甜。你每喝一次无非都在这些选项里排列组合(2*2*2种),比如超多糖、烫嘴、超多料;下次你换一种排列组合,无糖,多冰,无料;所有选项的排列组合全点了,那就是多corner。
蒙特卡罗Monte Carlo则是在上、下限之间无穷尽地取值进行排列组合。
这次你来到了一家新的奶茶店,名字叫无穷∞奶茶店,选项完全定制化。你可以在选择任意一个值,比如第一次你喝的是3分甜、少少冰、不加料;下一次觉得不够甜,不冰,你点了6.6分甜、7.8分冰、加两颗珍珠。
这样就会有出现无数种排列组合的奶茶,这就是蒙特卡罗Monte Carlo了。
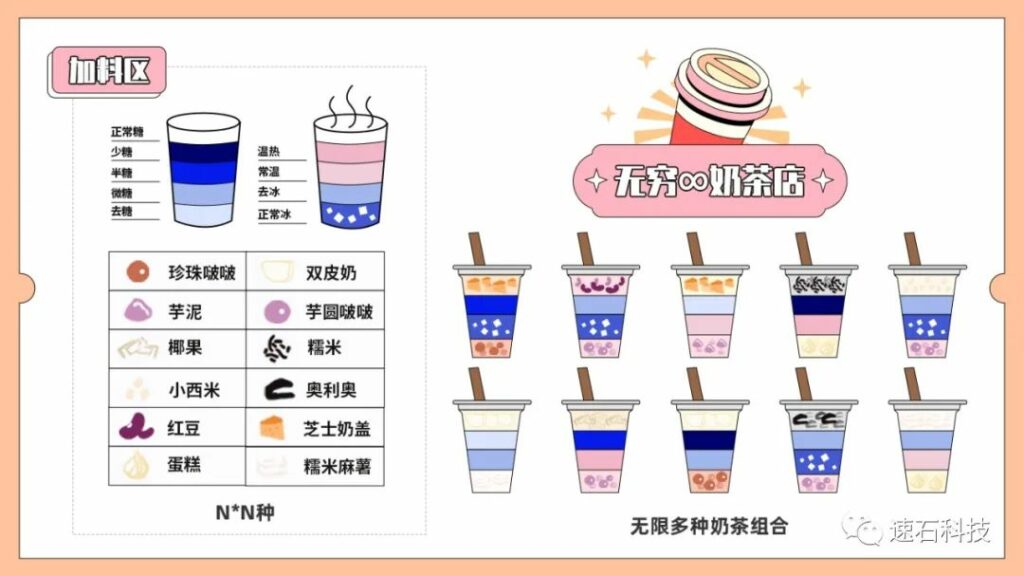
可取无数个组合的蒙特卡罗Monte Carlo可以用来估算良率的范围,随着取值组合越多,对工艺偏差导致的误差估计范围越准确,对实际的成品良率预测范围越准确,当然计算量也会成倍提高。
不管是哪家奶茶店,这杯奶茶与那杯奶茶之间互相独立,你喝你的,我喝我的。
这就是多corner和蒙特卡罗Monte Carlo任务特别适合分布式并行计算的本质原因。
不同任务,你算你的,我算我的,分开算,人多力量大。
不论是前仿还是后仿阶段,都需要大量多corner与蒙特卡罗Monte Carlo仿真。
两者相比,蒙特卡罗Monte Carlo仿真因为取值选择多,组合多,计算量明显比多corner大。
而前仿和后仿之间,后仿因涉及更多的物理参数,两种算法的计算量都会呈几何倍增长,算力需求也更大。
整体来说,这两种数值计算方法任务间独立,算力需求大,是我们帮用户提高效率的典型场景之一。
“大家来找茬”之版图验证任务
版图设计,就是把设计好的电路原理图变成包含实际布局布线规划内容的掩模版图,设计师每天在电路图上画花花绿绿的MOS管,确定要用多少元件、用哪种排列方法,在保证芯片电气性能的前提下,怎么跨层使得芯片体积最小、最省钱。
版图验证就是把画好的版图和原理图进行比对,确保两者的拓扑连接关系一致,同时检查版图是否符合foundry的设计工艺。
版图设计与验证,就像是在玩一个“大家来找茬”的游戏,首先几个版图设计师先一起把这张图分工合作给画出来。到了版图验证阶段,就开始正式玩找茬游戏了。目的是检查版图有哪些地方不对,有问题的话,打回去重新画。画完再继续检查,循环往复。
如果使用“小F影分身术”(版图分割术),可以把小F分为9个影子,每个影子只需负责找茬九分之一个版图,影分身的数量越多(版图切割的任务数)越多,分配的资源数越多,单位效率越高(当然,版图大小有个物理上限,没必要走极端)。
更重要的一点,切割版图与找茬任务之间互不干扰,你改你的,我改我的。你改完了重新提交下一轮,也不影响我还在上一轮。中间也不用因为等待而停工。
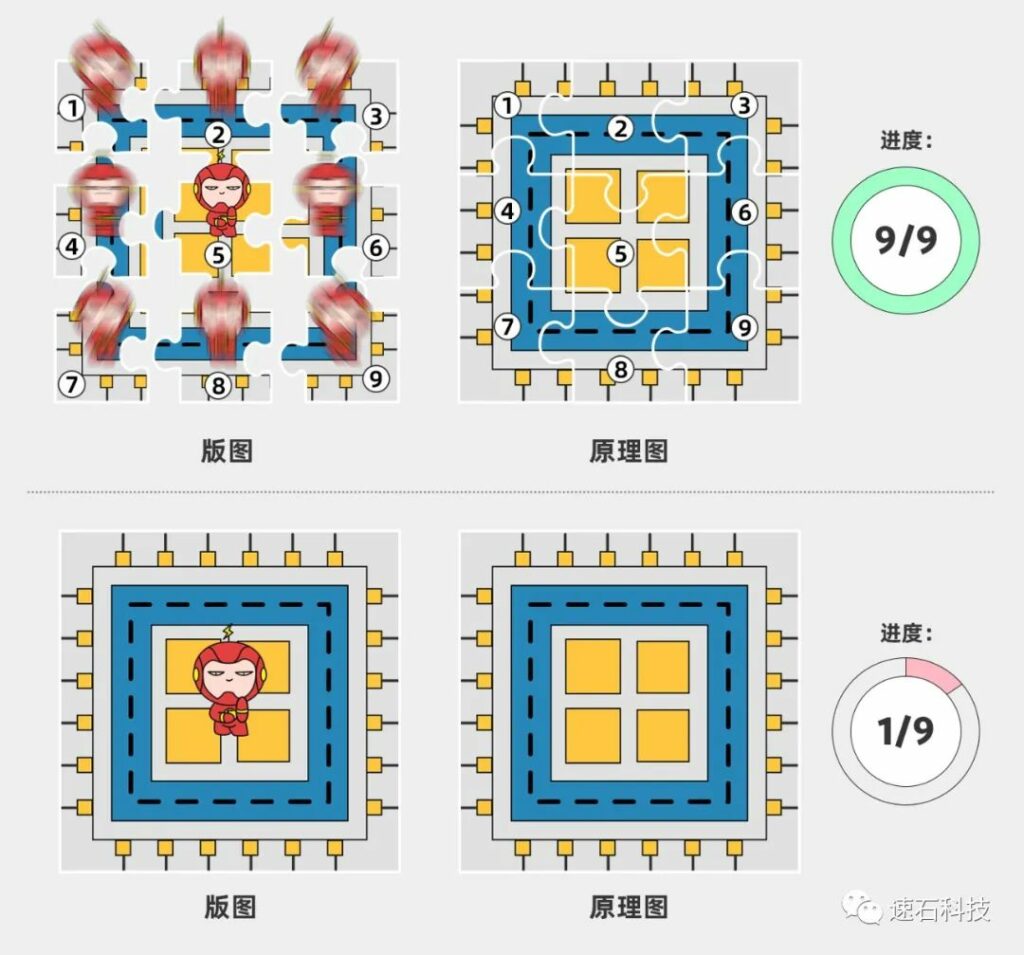
切割版图并合理分配资源的检查方法,可以让版图设计师无需苦苦等待一台计算机对单个大版图各部分逐一检查,而可以让多台计算机并行检查同一张大版图的不同部分,并自动汇总结果。这样一来就能更快地完成任务。
版图、原理图对比与设计规则检查同属检查类任务,都是以模块为单位,本质上是数据对比工作、重内存需求、子任务间没有数据关联,是一种高并行度任务。因此这一阶段很适合在云上使用内存优化型资源,通过暴力堆资源的方式快速完成任务。
模拟电路王冠上的明珠--射频电路
射频芯片作为模拟电路王冠上的明珠,一直被认为是芯片设计中的“华山之巅”。
一方面因为射频电路的物理形状和周围介质分布会对射频信号的传输造成很大影响,因此设计之路十分困难,前期需要进行大量仿真测试,而且为了保证高频性能,材料的选取也十分讲究,比如砷化镓和氮化镓。
另一方面,为了保证射频芯片各类指标的性能均衡,很多指标的性能要求都需要挑战工艺极限或设计创新性的电路结构,十分考验工程师的经验积累。
而射频需要使用电磁场仿真,需要计算三维空间向量。
如果说版图是将二维世界切成一片片的,那射频就是将立体空间切成一粒粒的,当然更具挑战性,算力需求也会呈指数级增加。
当遇到CPU无法满足的情况,不妨尝试使用GPU处理,他们可是处理向量计算的一把好手。
目前射频电路电磁场仿真的三种常用软件分别为:HFSS、EMX、ADS。
HFSS处理智能制造/汽车制造场景下的电磁场仿真较多、也支持部分芯片设计场景,EMX和ADS处理芯片设计场景的电磁场仿真更为广泛。其中,HFSS和19版之后的ADS支持GPU处理电磁场仿真任务,且通过并行化处理后,效率提升十分显著;EMX作为Cadence里的万能插件暂不支持GPU任务。
关于计算量级的本质
单模块、多模块和top级任务是三种计算量级的任务,从字面上就能猜到单模块任务,计算量最少;以此递增,top级任务计算量最多。
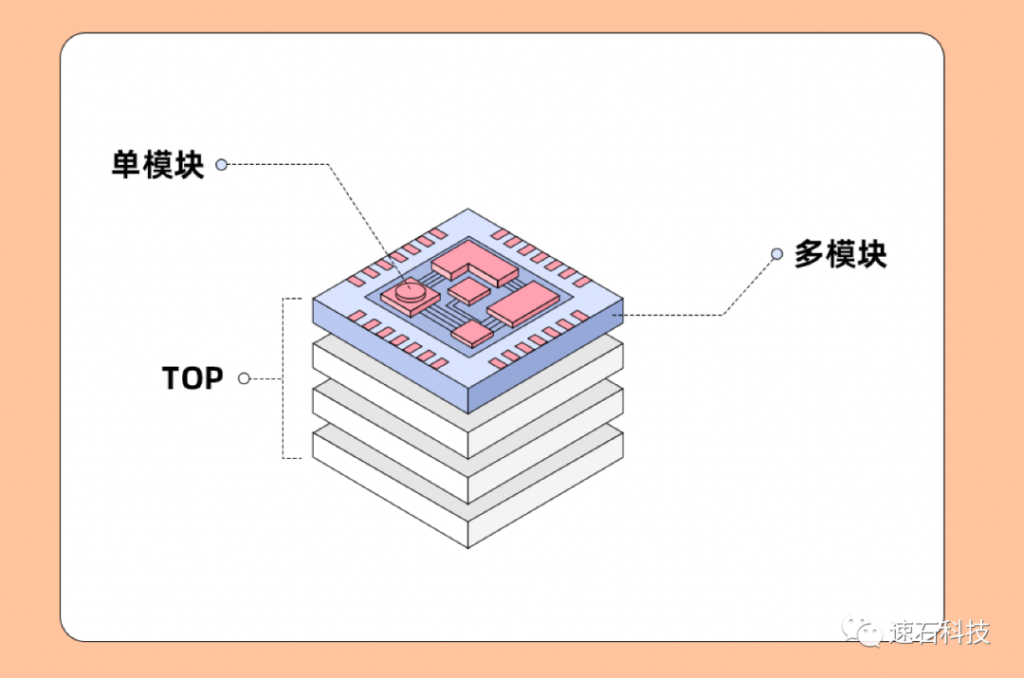
单模块任务指的是单一模块的任务,比如单层上的某个元器件就是一个单模块任务,计算量级最小,可能可以继续拆,也可能是最小不可拆分任务;
多模块任务指的是多个单模块合并在一起的任务,比如一层上的多个元器件组合在一起的模块,计算量级中等,可将多个模块拆分进行多线程处理;
top级任务,字如其名,是整个芯片设计阶段最大规模的仿真,将整个芯片的全部功能模块聚在一起,做全功能验证。top级仿真是在顶视图下的一整套前仿或后仿,算力需求最高。
如果涉及到先进工艺(28nm以下芯片),更小的空间,更多的模块,更复杂的PDK工艺库,计算量呈指数级增长。而且先进制程芯片后仿时还要做IR Drop的独立性检查,是SignOff的一个必要步骤。业内在该步骤使用的工具大多为Redhawk,和DRC/LVS的算法流程基本一致。
关于模拟IC设计,从不同设计阶段的计算任务视角出发,我们总结了三点:
1、三大阶段的算力需求呈现前期<中期<后期的趋势。和波谷相比,峰值算力最高可达到百万级别,使用弹性云端资源可以高效且动态地满足峰值需求;
2、多corner、蒙特卡罗Monte Carlo以及DRC、LVS这类任务,非常适合直接用多机并行来提升任务效率;
3、基于单模块不可拆的任务,虽不能做到多机分布式处理,但可以通过上大内存、高主频机型,靠机器的性能实现任务效率的提升。
说到这,模拟IC篇就结束啦,敬请期待我们的第二集--数字IC!
关于fastone云平台在其他应用上的表现,可以点击以下应用名称查看:
HSPICE │ Bladed │ Vina │ OPC │ Fluent │ Amber │ VCS │ MOE │ LS-DYNA│Virtuoso│ COMSOL
- END -
我们有个IC设计研发云平台
集成多种EDA应用,大量任务多节点并行
应对短时间爆发性需求,连网即用
跑任务快,原来几个月甚至几年,现在只需几小时
5分钟快速上手,拖拉点选可视化界面,无需代码
支持高级用户直接在云端创建集群
扫码免费试用,送200元体验金,入股不亏~

更多电子书
欢迎扫码关注小F(ID:iamfastone)获取
你也许想了解具体的落地场景:
王者带飞LeDock!开箱即用&一键定位分子库+全流程自动化,3.5小时完成20万分子对接
这样跑COMSOL,是不是就可以发Nature了
Auto-Scale这支仙女棒如何大幅提升Virtuoso仿真效率?
1分钟告诉你用MOE模拟200000个分子要花多少钱
LS-DYNA求解效率深度测评 │ 六种规模,本地VS云端5种不同硬件配置
揭秘20000个VCS任务背后的“搬桌子”系列故事
155个GPU!多云场景下的Amber自由能计算
怎么把需要45天的突发性Fluent仿真计算缩短到4天之内?
5000核大规模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina对接2800万个分子
从4天到1.75小时,如何让Bladed仿真效率提升55倍?
从30天到17小时,如何让HSPICE仿真效率提升42倍?
关于为应用定义的云平台:
【ICCAD2022】首次公开亮相!国产调度器Fsched,半导体生态1.0,上百家行业用户最佳实践
解密一颗芯片设计的全生命周期算力需求
居家办公=停工?nonono,移动式EDA芯片设计,带你效率起飞
缺人!缺钱!赶时间!初创IC设计公司如何“绝地求生”?
续集来了:上回那个“吃鸡”成功的IC人后来发生了什么?
一次搞懂速石科技三大产品:FCC、FCC-E、FCP
速石科技成三星Foundry国内首家SAFE™云合作伙伴
EDA云平台49问
亿万打工人的梦:16万个CPU随你用
帮助CXO解惑上云成本的迷思,看这篇就够了
花费4小时5500美元,速石科技跻身全球超算TOP500